1. 도입
natural language processing은 인간의 언어를 이해하고 해석하는데 중점
text analytics는 비정형 데이터에서 의미있는 정보를 추출하는데 중점
NLP는 TA를 향상하게하는 기반 기술이라고 볼 수 있다.
NLP는 기계번역, 질의응답에서 활용된다. 룰 기반 방법에서 머신러닝이 등장하면서 많은 발전이 있었다.
TA는 business intelligence(기업에서 사용하는 것), 예측 분석, text classification, sentiment analysis, summarization, clustering에 쓰인다.
1) text classification의 예시는 신문 기사를 분류하거나 스팸메일을 분류하는 것이 있다.
2) setiment analysis의 예시는 소셜 미디어에서의 감정 분석, 영화나 제품에 대한 긍정, 부정 리뷰, 여론조사 등이 있다.
3) summarization은 중요 주제나 중심 사상을 추출하는 것이다.
2. 텍스트 분석 이해
텍스트 분석은 비정형 데이터인 텍스트를 분석하는 것이다.
비정형 데이터를 feature형태로 추출하고 추출된 feature에 의미있는 값을 어떻게 부여하는가?
이 문장을 예시를 넣어서 다시 말해보면, word에서 다수의 feature를 추출하고 이 피처에 단어 빈도수와 같은 숫자 값을 부여하면 텍스트는 단어의 조합인 벡터값으로 표현될 수 있다. 이와 같은 과정을 feature extraction 혹은 feature vectorization라고 부른다.
비정형 데이터(문서) -> feature 추출(word 추출) -> 의미부여(단어 빈도수..등)
feature extraction에는 BOW, Word2Vec 방법이 있다.
텍스트 분석 수행 프로세스를 좀 더 확실하게 알아보자.
여기서 중요한 것은 어떤 방법을 사용해서 단어를 벡터로 만들어도 미리 텍스트를 가공해야한다는 점이다.
1. text preprocessing
텍스트를 피쳐로 만들기 전 클렌징(대/소문자 변경, 특수문자 삭제), 토큰화, stop words 제거, 어근 추출(stemming, lemmatization)을 거친다.
2. feature extraction
refined dataset을 통해서 feature을 추출하고 벡터화시킨다.
(BOW에는 count, TF-IDF 방법이 있고, word2vec에는 skip-gram과 cbow가 있다.)
3. modeling
feature vectorization이 완료된 feature을 모델에 적용하여 train/eval/test 과정을 거친다.
**텍스트 분석 패키지
NLTK: 모든 것이 갖추어져있지만, 성능면에서 떨어져 대용량에는 좋지않다.
gensim: topic modeling에 좋다.
spaCy: 성능이 좋아서 application에서 자주 사용된다.
sklearn: 기본적인 것만 제공한다.
3. Text preprocessing(텍스트 정규화)
cleansing, tokenization, stop words & filtering, stemming, lemmatization
클렌징, 정제, 토큰화, 어근화
실습
1) 클렌징
분석에 필요없는 문자, 기호 등 삭제 Ex. html, xml tag ..
2) 텍스트 토큰화
-문장 토큰화 ( 단어의 순서가 중요한 경우 - sematic이 중요, word2vec )
문장의 마침표, 개행문자(\n), 정규표현식에 따라 문장을 분리해서 리스트에 string 형태로 담아둔다.
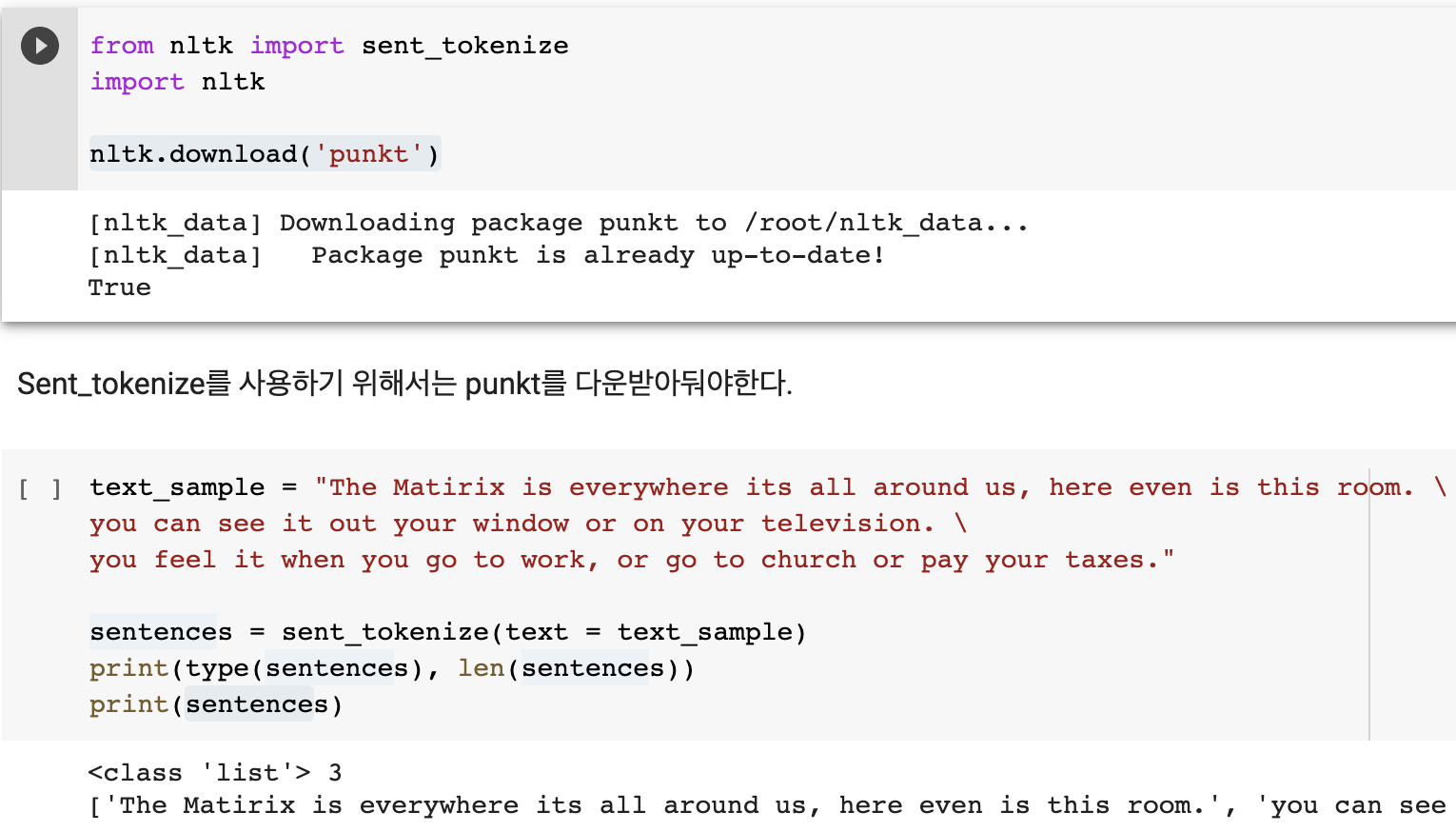
-단어 토큰화 ( 단어의 순서가 중요하지 않은 bag of word는 단어 토큰화만 사용해도 괜찮다 )
문장을 단어로 토큰화하는 방법이다. 공백, 콤마, 마침표, 개행문자, 정규 표현식을 이용한다.

- 모든 단어를 토큰화 ( 문서 -> 문장 -> 단어 )
sent_tokenize, word_tokenize를 조합하면 된다.

-추가
문장을 위처럼 단어별로 하나씩 토큰화 할 경우 문맥적인 의미는 무시될 수밖에 없습니다.
이러한 문제점을 해결하기위해서 n-gram을 사용합니다. n-gram은 연속된 n개의 단어를 하나의 토큰화 단위로 분리해 내는 것입니다.
예를 들어서, bi-gram이 있습니다. word2vec의 window_size를 생각하면 됩니다.
3) stop word 제거
문장에는 is, this, whom, what 처럼 그냥 문법적으로 자주 사용되는 단어(=문맥적으로 큰 의미가 없다)가 있다. 이 단어들을 지워줘야 실제 문서가 담고있는 의미를 파악하는데 효과적이다. 따라서 nltk에서 stopwords를 사용한다.
문서를 문장으로 나누고 단어로 나누고 각 단어들이 stopwords에 속하는 지 확인하면서 stopwords에 속하면, filtering을 한다.
stopwords = nltk.corpus.stopwords.word('english')

-한글판 stopwords
4) stemming, lemmatization
work가 working, works, worked로 happy가 happier, happiest처럼 언어는 다양하게 변화한다. 따라서 이 방법은 단어의 원형을 찾는 것이다.
stemming에는 porter, lancaster, snowball stemmer가 있는데, 간단한 문법적인 요소만 파악하여 원형으로 바꿔준다.
lemmatization에는 wordnetlemmatizer이 있는데, 문법적인 요소를 제외하고도 의미적인 부분을 감안해 정확한 어근 단어를 찾아준다.
대신, 시간이 더 걸리고 품사를 입력으로 줘야한다.
예를 들어서, stemming은 worked, works, working처럼 work에서 단순히 ing, ed, s가 붙은 것은 구분을 하지만 happy에서 y가 ier, iest로 변하는 happier, happiest는 구분하지 못한다.


4. feature vectorization or feature extraction - BOW
문서가 가지는 모든 단어의 문맥이나 순서는 무시하고 무조건 빈도 수를 부여해 피처 값을 추출하는 모델이다.
문장의 모든 단어에서 중복을 제거하고 각 단어를 컬럼 형태로 나열해서 각 단어에 고유한 인덱스를 부여하고 빈도 수를 값으로 부여한다.
장점) 쉽고 빠른 구축
단점) sematics를 담기 어렵다 -> 보완 n-gram
메모리 낭비 -> dense feature로 바꿀 수 있다.
*BOW모델에서 Feature vectorization
"모든 문서"에서 "모든 단어"를 column형태로 나열한다. 그리고 행에 모든 문서를 나열해서 각 문서마다 나오는 단어들을 빈도 수대로 채워준다.
일반적으로 두 가지의 feature vectorization방법이 있다.
-count
-TF-IDF (term frequency, inverse document frequency)
모든 문서에서 전반적으로 자주 나타나는 용어에 패널티를 준다. 예를 들어서 분쟁, 종교대립, 유혈 사태와 같은 단어가 자주 등장하는 문서는 지역 분쟁과 관련된 문서일 확률이 높다. 반면에 빈번하게, 많게, 당연히 등 보편적으로 많이 사용되는 단어라면 문서의 틍징과 관련성이 적다. TF를 곱하고 DF를 나눠준다고 생각하자.
- sklearn, CountVectorizer, TfidfVectorizer
소문자 일괄 변환, 토큰화, 스톱워드 필터링 등의 텍스트 전처리를 하고 피처 벡터화된 객체를 반환합니다.
*프로세스
1) 사전 데이터 가공 - 소문자로 바꾸기
2) 토큰화 - n-gram-range 반영하여 토큰화 수행
3) 텍스트 정규화 - stop words 필터링만 수행 ( stemmer, lemmatize는 지원하지 않음 )
4) 피쳐 벡터화 - token된 단어들을 feature extraction 후 vectorization 적용
5. bow 벡터화를 위한 희소 행렬
아무래도 모든 문서의 단어를 컬럼으로 만들면 수만개의 컬럼이 생기기때문에 각 문서마다 없는 단어도 많아서 0이 많게되고 즉, 희소행렬이 발생한다. 그런데 이렇게 희소행렬을 사용하면 메모리 문제나 시간 문제가 생길 수 있기때문에 COO, CSR 형태의 희소행렬을 사용한다.
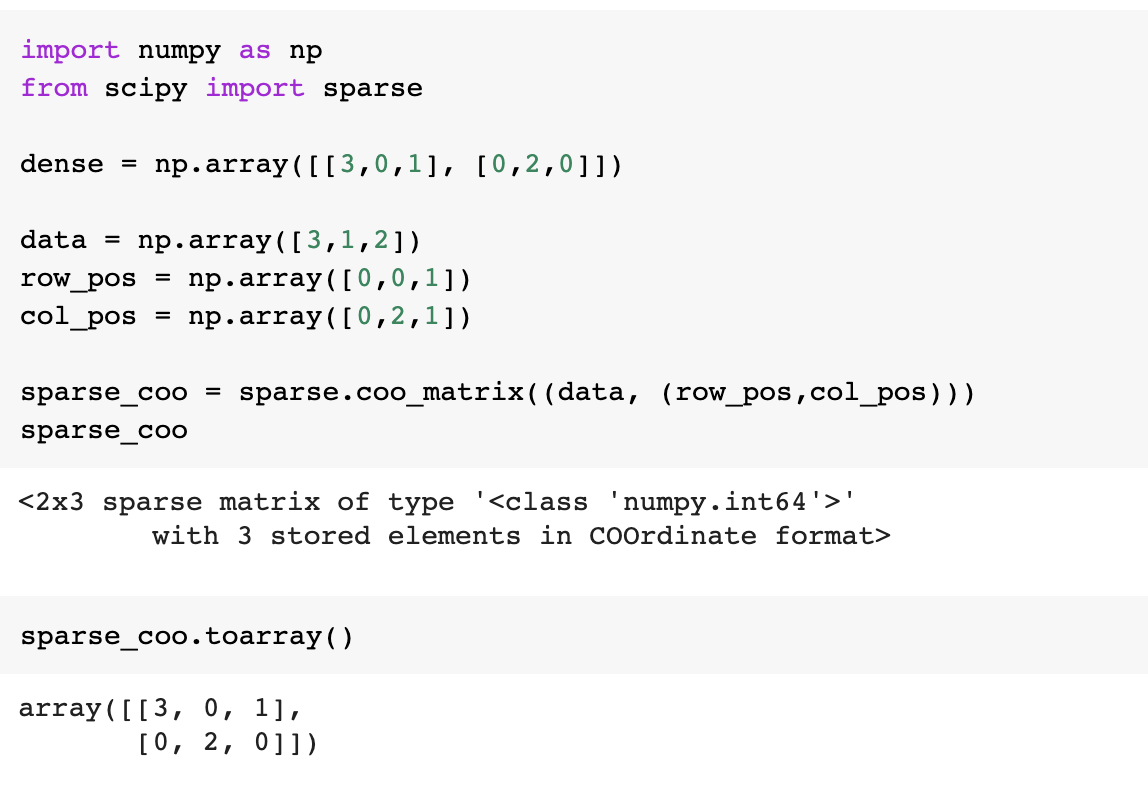
1) COO (coordinate:좌표)
주어진 희소행렬에서 3개의 리스트로 나눠서 표현하는 방법이다. 0이 아닌 데이터만 별도의 리스트에 저장, 그 데이터가 가리키는 행의 위치도 별도의 리스트에 저장, 그 데이터가 가리키는 열의 위치도 별도의 리스트로 저장한다. 이와 같은 희소행렬 변환을 위해서 Scipy 패키지의 sparse를 사용한다.
2) CSR (compressed sparse row)
"행 위치 배열"내에 있는 고유한 값의 시작 위치만(ex. 1,2,...) 다시 별도의 위치 배열로 가지는 변환 방식을 의미합니다.
행 위치 배열 = [0,0,1,1,1,1,1,2,2,3,4,4,5]
배열의 인덱스 0 1 2 3 4 5 6 7 8 9 10 11 12
-> [0,2,7,9,10,12] + [13] 총 갯수


정리하자면 bow방식을 사용하면 대부분 희소행렬이 발생해서 메모리 문제가 발생하는데, 이때 COO, CSR 방식을 사용하면 이를 해결할 수 있다. 그리고 sklearn countervectorizer, tfidfvectorizer 모두 피처 벡터화 행렬은 모두 CSR 희소 행렬이다.
총정리. 질의응답, 기계번역, 텍스트 분류, 감정분석 등에 활용되는 텍스트 분석은 문서로부터 클렌징, 스타워드 필터링, stemming, lemmatization, tokenization을 통해서 전처리를 거쳐서 refine된 단어를 뽑아내고 이를 feature로 바꿔서 bag of words, word2vec둘 중 하나를 사용해서 feature vectorization을 한다. 그리고, 이 dataset을 모델에 넣어서 학습/검증/실험의 과정을 거친다. 토큰화에는 문장토큰화와 단어토큰화가 있는데, bag of words에서는 순서를 고려하지 않아서 단어 토큰화만 사용해도 되는데 이때 보완하기위해서 n-gram을 사용하기도 한다. 보통 맥락이 중요할때 문장토큰화를 사용하고 단어토큰화를 사용한다. stopwords는 단어들에서 문장을 뽑아서 단어를 뽑아서 stopwords에 있는 것만 필터링한다. lemmatizer은 wordnet을 사용한다.
bow는 모든 문서의 모든 단어를 컬럼형태로 나열을 하고 모든 문서를 행형태로 나열을 하면 엄청나게 큰 희소행렬이 완성된다. 이 행렬에는 빈도수를 기준으로 피쳐마다 벡터화 시켜준다. 이렇게 하면 빠르고 쉽게 구축한다는 장점이 있지만 의미를 담기힘들고, 메모리가 낭비된다는 단점이 있다. 그래서, CSR, COO 형태의 희소행렬로 바꿔준다. 그리고 bow에는 count, tfidf 방식의 방법이 있다. tfidf는 모든 문서에서 자주 등장하는 단어 예를 들어서, 빈번하게 많게 ..와 같은 단어에 대해서는 특정 문서에서 중요한 단어가 아니기때문에 패널티를 주는 방식이다. 이는 document frequency를 역수로 곱해서 패널티를 부여한다. 이와 반대로 전체 문서에서는 나타나지 않지만 특정 문서에서만 잘 나타나는 단어는 패널티를 적게 부여한다. 실제 sklearn의 countervectorizer, tfidfvectorizer은 위에서 말한 전처리 과정을 거쳐서 피쳐를 벡터화하고 CSR형태로 희소행렬을 저장한다.
-> 문서에서 클렌징,stopwords,stemming,lemmatization,tokenize 등의 전처리를 통해 단어를 준비하고 bag of words,word2vec 같은 Feature vectorization을 통해서 벡터로 바꾼다. 즉, 문서의 단어들을 벡터로 표현했다.
'이제는 사용하지 않는 공부방 > Artificial intelligence' 카테고리의 다른 글
| [자연어처리] (3) sentiment analysis 실습 (0) | 2021.06.09 |
|---|---|
| [자연어처리] (2) 텍스트 분류 실습 (0) | 2021.06.09 |
| [밑바닥부터 시작하는 딥러닝2] word2vec (0) | 2021.06.05 |
| [tensorflow] 텐서플로우 여러가지 기능 (0) | 2021.06.02 |
| [추천시스템] (3) LearningToRank 실습정리 (0) | 2021.05.29 |