자연어처리 학습 후, 텍스트마이닝에 적용하는 과정 학습
1. 자연어처리에 대해서 알아본다.
(활용: 리뷰 분석 피드백 반영, 경쟁사 분석, 고객 분석)
2. 학습에 용이하도록 데이터 전처리하는 방법을 알아본다.
3. 단어와 문서 표현방법을 알아본다.
4. 통계기반 방법으로 텍스트 마이닝하여 대량의 문서에서 인사이트를 도출하는 방법을 학습한다.
Part1.
1강 자연어처리 소개
2강 자연어처리의 활용
Part2.
3강 텍스트 분석
4강 텍스트 전처리
토큰화, 품사태깅, 원형복원, 불용어 처리
Part3.
5강 문서의 표현
단어의 표현(TF-IDF, ONE-HOT), 문서의 표현(BoW, TDM, TF-IDF)
Part4. 텍스트마이닝 기법
6강 핵심 키워드 추출 ( Text Rank )
7강 문서 요약
8강 문서 분류 ( naive bayes )
9강 감정 분석
1강 자연어처리 소개
1)정의
자연어처리란 자연어로 명령을 내리면 기계가 이해하여 결과를 제공할 수 있도록 하는 것이다.
2)동기
- 메일, 소셜미디어와 같은 비정형 데이터가 많은 비중을 차지함에 따라서 중요성이 높아지고 있다.
- 온라인에서 기업의 평판이 중요해지고 있다.
- 소통 패러다임의 변화 ( 키보드 → 대화형 )
3)어려운 점
동음이의어나 다의어처럼 언어가 가지는 모호성이 어렵게 한다.
특히, 한국어는 아래와 같은 이유로 더 어렵다.
- 구어와 문어의 차이 (문법)
- 띄어쓰기의 존재 (아버지가 방에, 아버지 가방에)
- 높임법의 존재
- 동음이의어 (안녕!, 안녕~)
- 주어 서술어 목적어의 생략
4)한계점
- 도메인 의존적
- 결과가 정확한지 판단 어려움 (감정분석시 사람의 주관 아닌가?)
2강 활용사례
1)실시간 리뷰 모니터링
고객들이 리뷰를 보고 구입을 결정하는 경향성이 큰데 이를 실시간 모니터링하며 대응할 수 있다.
2)경쟁사 분석
자사와 타사의 온라인 데이터를 분석하여 어떤 점이 우세고 열세인지 그리고 원인이 무엇인지 인사이트를 얻고 전략을 수립할 수 있다.
3)뉴스레터, sns 포스팅 자동화
뉴스에서 nlp로 핵심 키워드, 요약분석을 통해 분석시간을 대폭 줄일 수 있다.
4)고객분석
리뷰나 블로그 등을 자연어 처리로 분석하여 진짜 고객을 알 수 있다.
(성별, 나이, 지역, 직업 등)
위의 4가지 모두 리뷰, sns, 뉴스 등에서 웹크롤링을 통해 데이터를 추출하고 이를 자연어 처리하여 긍정, 부정, 중립 등등 다양한 결과를 도출하는 것이다.
Part2
3강 텍스트 분석과정
데이터 수집 → 전처리 → 분석 → 시각화
데이터 수집
웹크롤링을 통해 광고, 메뉴, 인기기사 링크 등 불필요한 내용을 제거하고 필요한 데이터를 수집한다.
(공개된 api 활용, 검색, 현장 수집을 통해 얻을 수도 있다.)
전처리
tokenizing(토큰화), stemming, lemmatizing(표제어 추출), pos tagging(품사 태깅)을 통해서 학습에 사용할 수 있도록 데이터 전처리를 한다.
분석
- topic modeling: 특정 문서에서만 빈도 높은 단어를 추출한다.
- summarization: 주요 문장을 찾아서 요약한다.
- classification: 문서를 주제에 따라서 분류한다.
- sentiment analysis: 문서에 대한 사람들의 태도, 감정을 분류한다.
시각화
- word cloud: 핵심 단어를 사용자가 한눈에 파악할 수 있다.
- sentiment pie chart: 긍정, 부정, 중립의 정도를 한눈에 파악할 수 있다.
4강 텍스트 전처리
유의미한 정보는 유지하면서 효율성을 높이기 위한 과정
토큰화 → 품사 태깅 → 원형 복원 → 불용어 처리
질문. 개체명 인식 named entity recognition은 어떤 단계에 들어가나요?
토큰화 tokenization ( sentence, word )
영어는 공백으로도 충분하지만 한국어의 경우 품사를 고려하여 토큰화( = 형태소 분석)해야한다.
ex. 버락 오바마 는 후라이드 치킨 을 너무 좋아한다 .
*단어 토큰화 고려사항
- 특수문자 state-of-the-art → state/of/the/art (x)
- 띄어쓰기 new york → new/york (x)
품사 태깅 pos tagging
필요한 품사만 사용하고 불필요한 품사는 제거하기 위해 사용한다.
개체명 인식 named entity recognition
사람, 조직, 지역, 날짜 등 개체 유형을 식별하는 것으로 검색에서 주로 사용된다.
ex. 버락 오바마가 사람인지 아닌지 식별
ex. 삼성전자를 검색하면 삼성전자가 기업으로 인식된 결과만 추출
원형 복원 stemming, lemmatization
동기: [1:"좋아요", 2:"좋다" .... 102:"좋을까"] -> [1:"좋다"] 처럼 컴퓨터는 구분을 못하지만 결국에는 같은 의미기때문에 하나로 묶어준다. index를 줄일 수 있고 그 결과 연산의 효율성이 좋아진다.
- stemming: 품사를 무시하고 어간을 추출해서 부정확한 결과가 나올 수 있다.
- lemmatization: 품사를 고려하여 사전에 기반하여 원형을 추출하기때문에 정확하지만 사전에 없는 단어의 경우 out of vocab 에러발생한다.
따라서, 두 방법을 모두 사용하여 단점을 보완한다.
불용어 처리 remove stop words
불필요한 토큰을 제거한다.
part3
5강 문서의 표현
문서를 벡터로 표현하는 것으로 document representation라고 한다.
bag of words는 문서 내 단어의 빈도수를 통해 벡터로 표현한 것이다.
ex. I like blue banana and red banana → 01112110
1) TDM term document matrix
bag of words 방법을 통해 행렬로 표현한 것이다.
한계점:
순서를 고려하지 않는다.
sparse해서 메모리가 낭비되며 연산이 비효율적이다.
전처리가 매우 중요해진다. ( 같은 의미의 단어 표현이 있는 경우 다른 단어로 인식할 수 있다.)
자주 등장해도 중요한 단어가 아닐 수 있다. ( the, a... )
2) TF-IDF term frequency - inverse document frequency
TDM의 한계점을 극복하기 위해서 빈도수가 많아도 중요한 단어와 중요하지 않은 단어를 구분해준다.
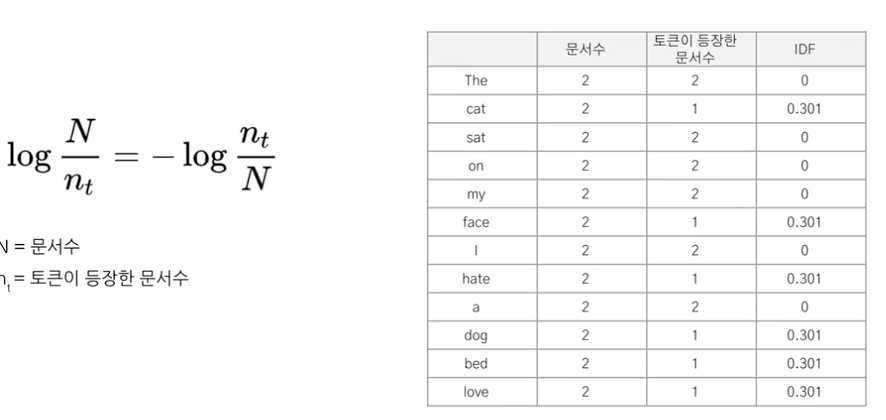
tf-idf(t,d,D) = tf(d,t) * idf(t, D)
(t는 특정 단어, d는 특정 문서, D는 전체 문서)
- tf(d,t): 특정 문서 d내 특정 단어 t의 빈도수
- df(t,D): 전체 문서 D에서 특정 단어 t의 출현 횟수
- idf(t,D): df의 역수
즉, 여러 문서에서 자주 등장하는 단어를 document frequency를 통해 알 수 있고, term frequency를 함께 고려하면 여러 문서가 아닌 특정 문서에서만 자주 등장하는 단어를 알 수 있다.
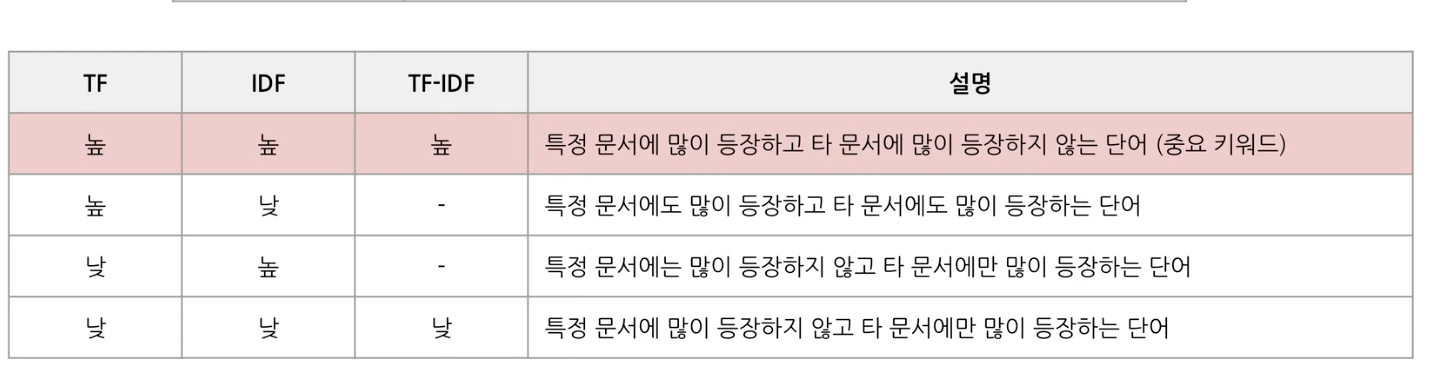
(3번째는 타문서에도 많이 등장하지 않는 단어)
tf-idf 계산 방법
tf와 idf를 계산하는 방법에는 관점에 따라 여러가지 방법이 있음

- tf
binary: 등장 유무파악
raw count: 순수하게 빈도수
term frequency: 전체 단어에서의 비율
log normalization: 큰 숫자를 로그를 통해서 작은 숫자로 변환해준다.
로그를 취하지 않을때 다른 단어들이 tf를 10,20..을 가지는데 특정 단어의 tf가 10million을 갖게 된다면 특정 단어의 tf-idf가 다른 단어들을 압도하게 되어 다른 단어들은 중요하지 않게 여겨질 수 있다. 로그 스케일을 취하면 큰 숫자가 작은 숫자로 줄어들어서 이를 방지할 수 있다.
라고 생각했는데, 영상에서는 1만과 9천이있을때 둘다 충분히 빈도수가 높기때문에 한쪽이 낮다고 할 수 없다고 하셨다. 따라서, 빈도가 증가할수록 그 차이를 감소하기 위해서 사용한다고 한다. → ??
double normalization 0.5: 특정 문서에서 빈도수가 가장 높은 단어로 나눠주기때문에 0.5 ~ 1로 범위를 맞춰줄 수 있다.
double normalization k: K ~ 1로 범위를 맞춰줄 수 있다.
참고
https://en.wikipedia.org/wiki/Tf–idf
- idf
unary: 등장 유무파악
idf: 전체 문서/특정 단어가 등장한 문서 수 ( df의 역수 )
idf smooth: 분모가 0이 되는 것을 방지하기 위함
idf max: nt 즉, 다른 문서에서 자주 등장한 단어로 idf가 가장 작은 것을 의미한다.
p idf: ??



결론적으로 tdm( using bag of words)의 한계점을 tf-idf를 통해서 해결했다.
6강
문서에서 핵심 단어 추출하는 것
단어의 중요성 판단하는 방법?
필요성?
통계적 접근 방법?
1단어빈도: 문서를 단어 모음으로 간주
의미, 구조, 문법 x
2연어/ 동시발생: n-gram 통계기법 사용하여 연어나 동시발생 단어를 하나의 단어로 처리
연이어 등장하는 단어 묶음 고객 서비스
동일 코퍼스 내에 함께 등장하는 단어 묶음, 반드시 인접할 필요x
1번 단어빈도를 활용한 tf-idf 활용 핵심키워드 추출
단어의 중요성 판단하는 방법? tf-idf
tf-idf score가 클수록 중요하다.
토큰화 -> tf-idf 계산 -> 상위 score 추출
2번 TextRank 활용 키워드 추출
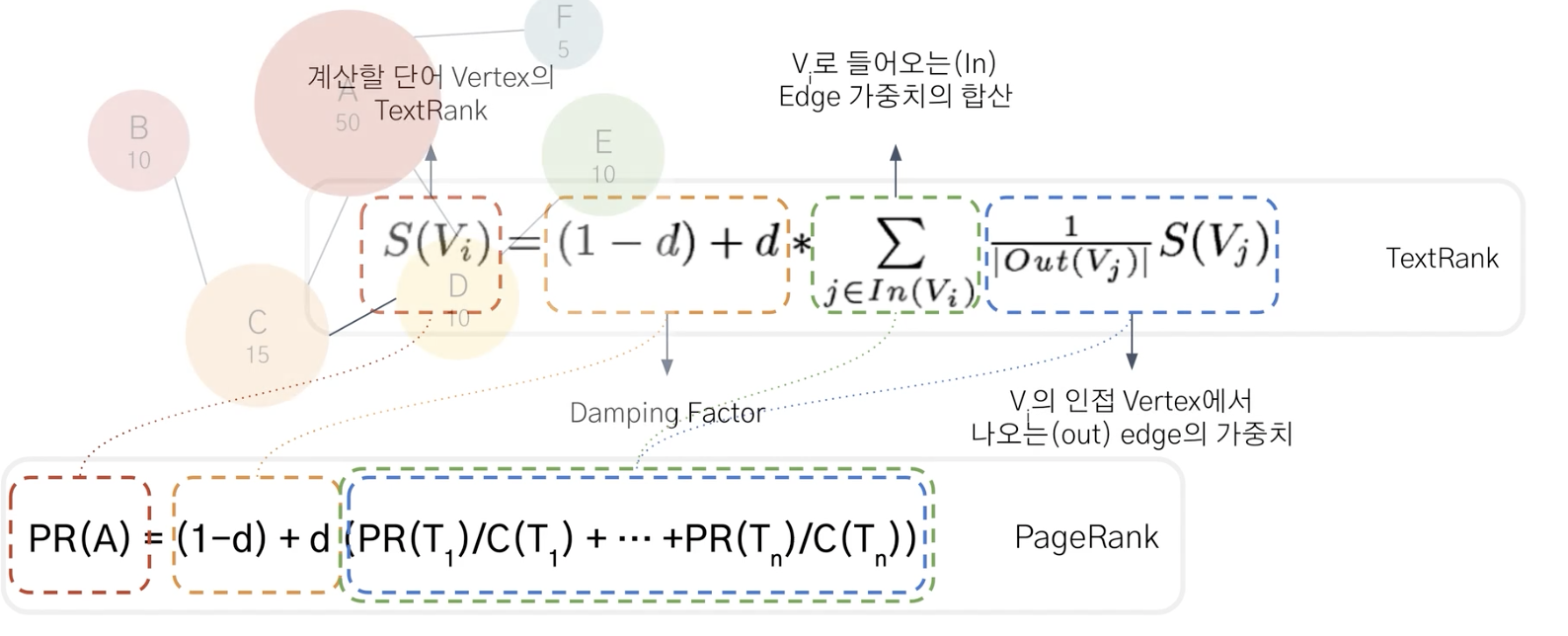
단어의 중요성 판단하는 방법? TextRank 그래프 기반
page rank -> text rank
page rank란? 검색결과에 순위를 정한다.
그래프에 기반하여 노드를 웹페이지라하고 엣지가 링크(인용)을 의미한다


A: B
T: D E F C 1.6 1.6 1.6
PR(T): 총 점수
C(T): 나가는 링크의 수, 1
d: damping factor: 이 페이지에서 다른 페이지로 이동할 확률
ex. d = 1이면, 100% 만족하지 못하고 다른 페이지로 이동할 것이다.
d = 0이면 만족하고 이동한다.
d = 0.85, 15%로 만족하지 못하고 다른 페이지로 이동할 것이다.
많은 페이지를 인용한 페이지가 인용하면 점수가 많이 오르지 않지만 적은 인용을 하고 인용을 많이 받은 페이지가 인용하면 점수가 많이 오른다.
text rank란?
brining order into Texts
abstract
그래프 기반의 랭킹 모델
단어의 중요도를 판단하는 방법이다.
핵심 단어 그리고 핵심 문장을 추출하는 비지도 학습방법을 제안하고 있다.
introduction
pagerank에서 쓰인 graph-based ranking algorithm은 그래프의 노드에 중요도를 부여하는 방법이다.
model: textrank
노드는 웹페이지 그리고 여기서는 단어를 의미한다. 하나의 노드가 다른 노드에 연결되면 추천하다고 보는 것이다.
많은 추천을 받은 노드가 중요한 노드가 된다.
undirected graphs - 결과가 더 빨라진다.
weighted graphs - 수렴속도가 빨라진다. 엣지로부터 score을 받는다.
undirected weighted graph를 사용한다.
text as a graph 텍스트를 그래프로 바꿔서 핵심 단어를 추출한다.
수식
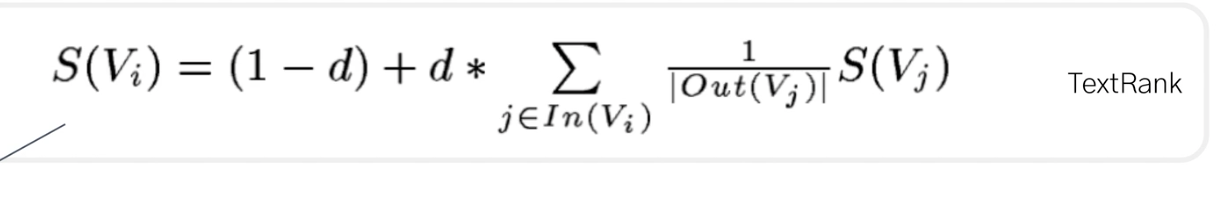
그런데 이렇게 중요도를 구해주면 왜 좋은 방법인거지?
- 텍스트 단위 (노드 단위)의 local context 고려뿐 아니라 전체 텍스트 (그래프)에서 정보를 고려하기 때문이다.
- 링크하는 다른 텍스트 단위의 중요성을 바탕으로 텍스트 단위를 평가
그럼 이제 가장 중요도가 높은 단어를 문서를 가장 대표적으로 표현하는 단어라고 할 수 있다.
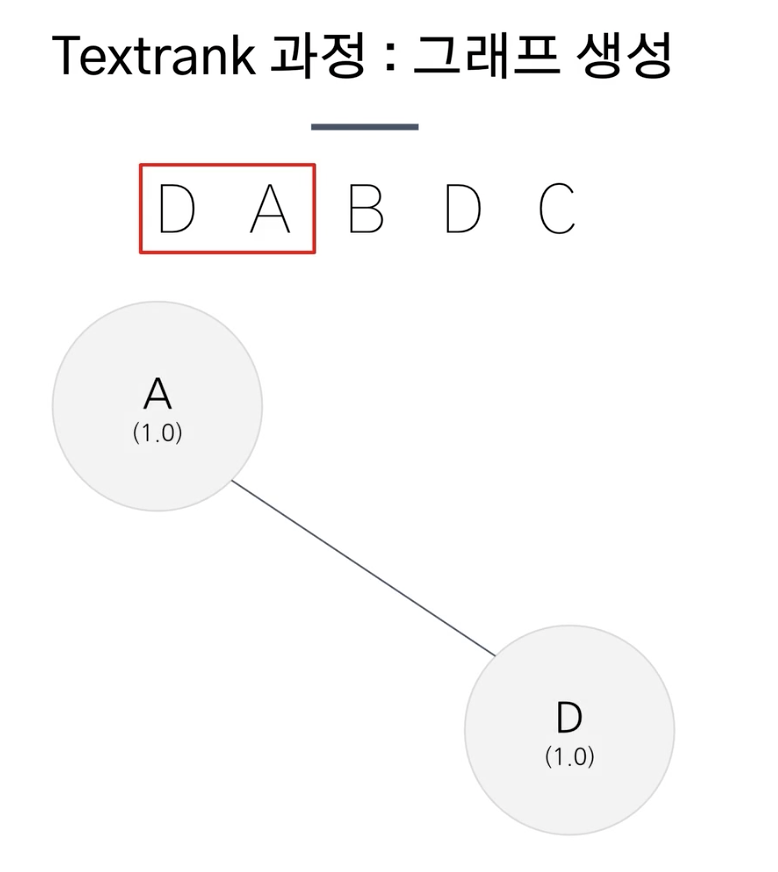
1단계 전처리 토큰화 -> 품사 태깅(명사, 동사)
2단계 window of words에 등장한 단어 사이에 엣지추가해서 그래프 생성
3단계 0.0001 로 해서 20-30번 반복하여 text rank score 산출
precision이 높다는 것은 정확성이 높지만 Recall이 낮다는 것은 지도학습방법이 낫다?
단어의 window size가 클수록 정확도가 떨어지는 데 이는 멀리있는 단어관계를 나타내지는 않는다는 것을 의미한다.
도메인에 독립적으로 사용할 수 있다.
실제 예시

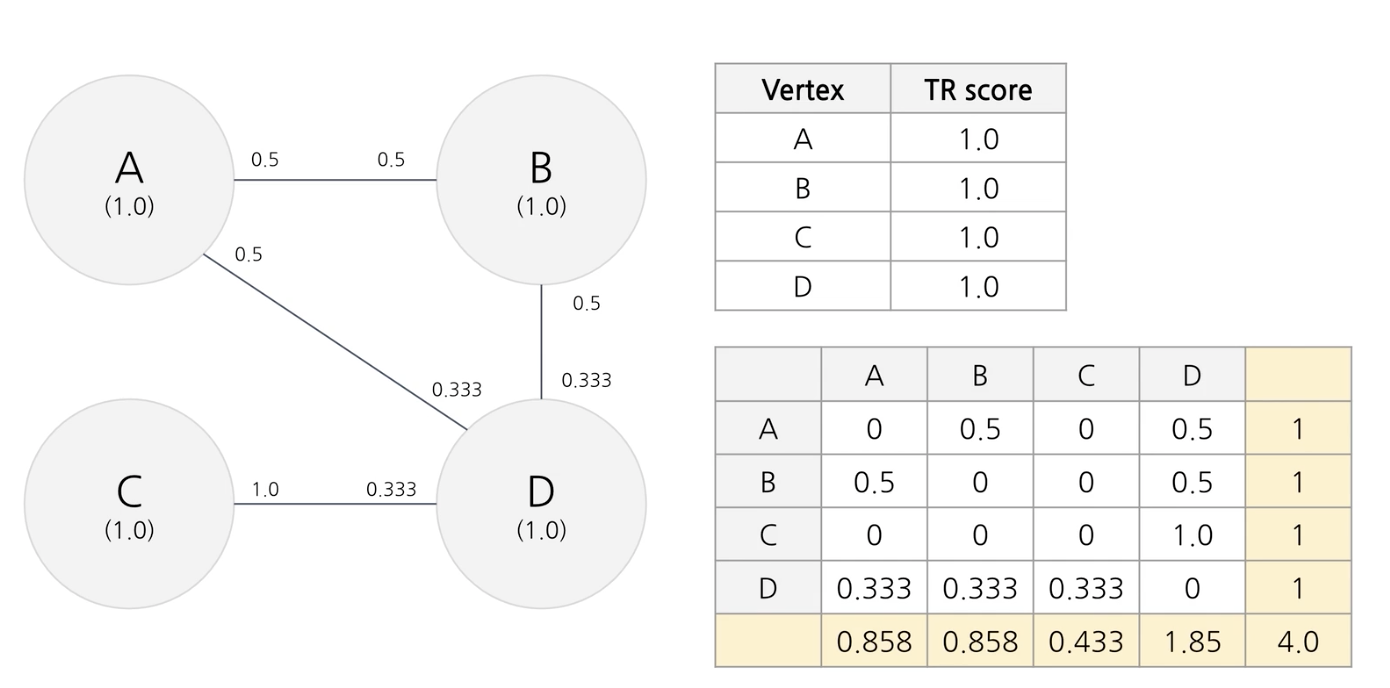


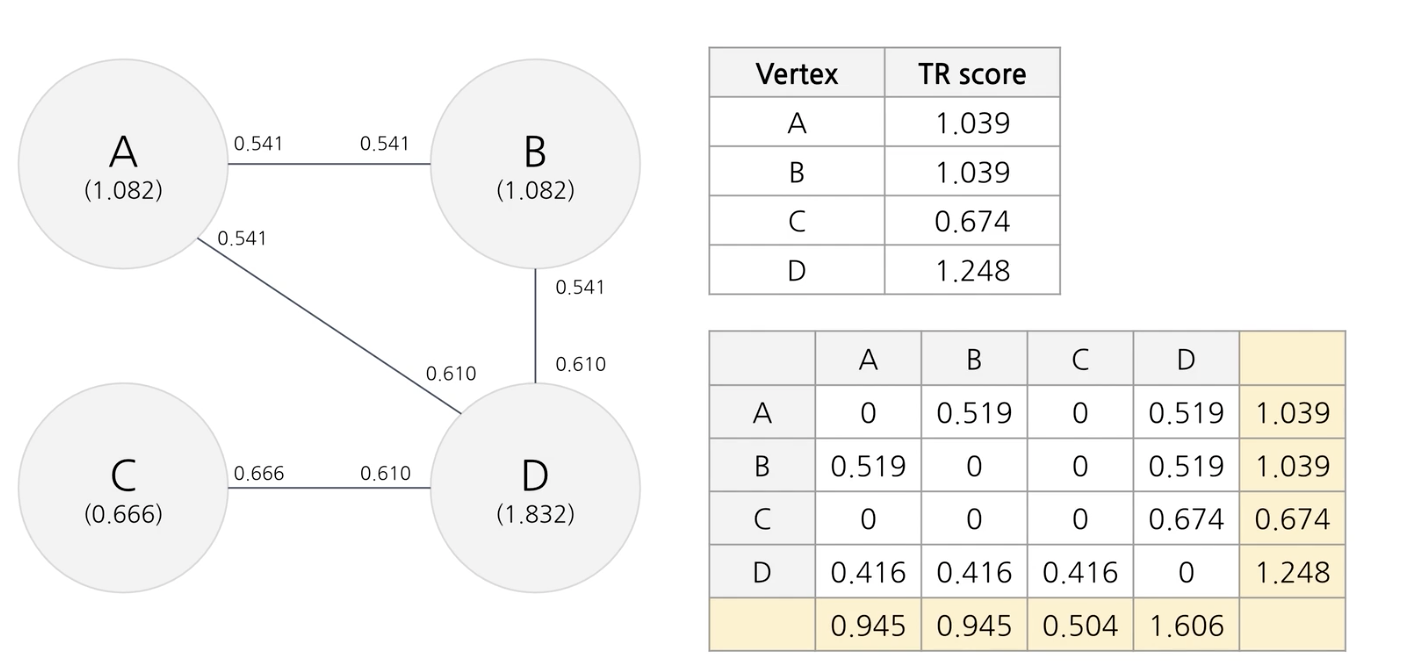

d 아닌가?
7강 문서 요약
중요 문장을 추출한다 어떻게 중요도를 판단하지?
문서 요약 == 핵심 키워드 추출
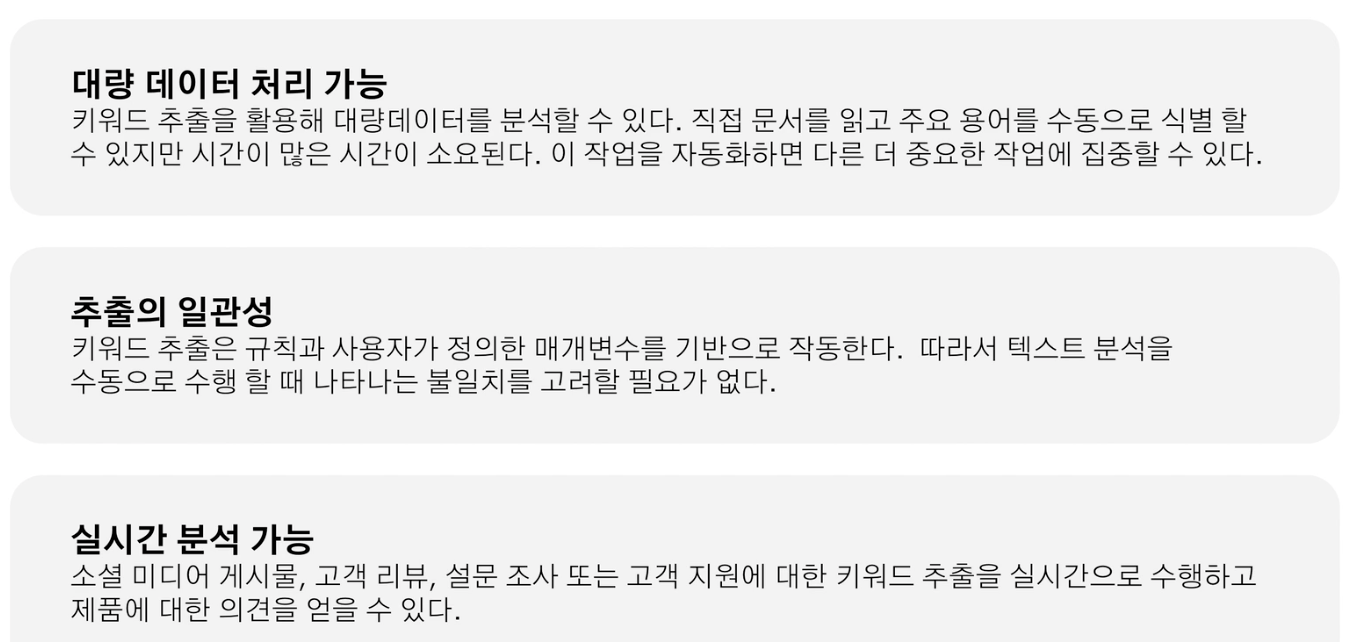
필요성
대량 데이터 처리, 추출의 일관성, 실시간 분석 가능
최초의 방법 luhn summarize
사용 빈도로 중요도를 판단한다. -> 일반적으로 중요한 단어를 반복해서 사용하기 때문이다.
단, 무조건 빈도수가 많다고 중요하다고 판단하지 않는다. 아래와 같은 기준을 사용한다.
전체 흐름
문서 토큰화 -> 토큰 빈도 비율 계산( 0.001 < 단어빈도비율 < 0.5 ) -> 문장 중요도 측정( 상대비율 ) -> 문장의 중요도 역순 정렬 및 출력

빈도수가 높은 곳에서, 중요한 단어와 중요하지 않은 단어 모두 빈도수가 높다. 따라서, resolving power가 낮다.
빈도수가 낮은 곳에서, 중요한 단어가 등장하기 어렵다. 따라서, resolving power가 낮다.
그래서 단어 빈도 비율이 특정 구간에 등장하는 단어로 중요 단어를 판단할 수 있다. ( 0.001 - 0.5 )
문장 중요도 판단

중요 단어가 등장한 시점부터 마지막으로 등장하는 시점까지의 중요 단어의 갯수를 알아야한다.
따라서 위와 같은 경우 4/7이고 이를 제곱하면 중요도가 2.3이 된다.
8강 문서 분류
문서를 분류하는 모델 ( 카테고리, 감정 분석, 언어 탐지 )
엔터 -> 사회 분류 -> 사회적인 문제가 발생했구나
모델
1)나이브 베이즈 분류
베이즈 정리 사용하는 모델: 학습 데이터에서 배운 사전 확률을 바탕으로 사후 확률을 계산하여 분류
불용어 처리, 원형 복원, n-gram(문맥), tf-idf로 성능 개선
2)서포트 벡터 머신
제한된 양의 데이터를 처리할 때 좋다.
나이브 베이즈보다 적은 데이터로 학습 가능하지만 나이브 베이즈보다 좋은 성능을 내기 위해서는 계산 리소스가 많이 필요하다
(리소스?)
3)딥러닝
(cnn, rnn, transformer)
데이터가 많을 수록 잘 작동하여 잘 태깅된 데이터가 필수다.
classifier 사전 지식
1) bayes classifier
데이터 중심의 분류기로 조건부 확률에 기반한다.
범주형 자료만 사용한다. (수치형 자료 -> 범주형 자료)
좋은 성능을 위해 대량의 데이터가 필요하다.
exact bayes classifier, naive bayes classifier가 있다.
2) 확률
사건이 발생할 가능성
관심사건(A)/표본공간(S) = %
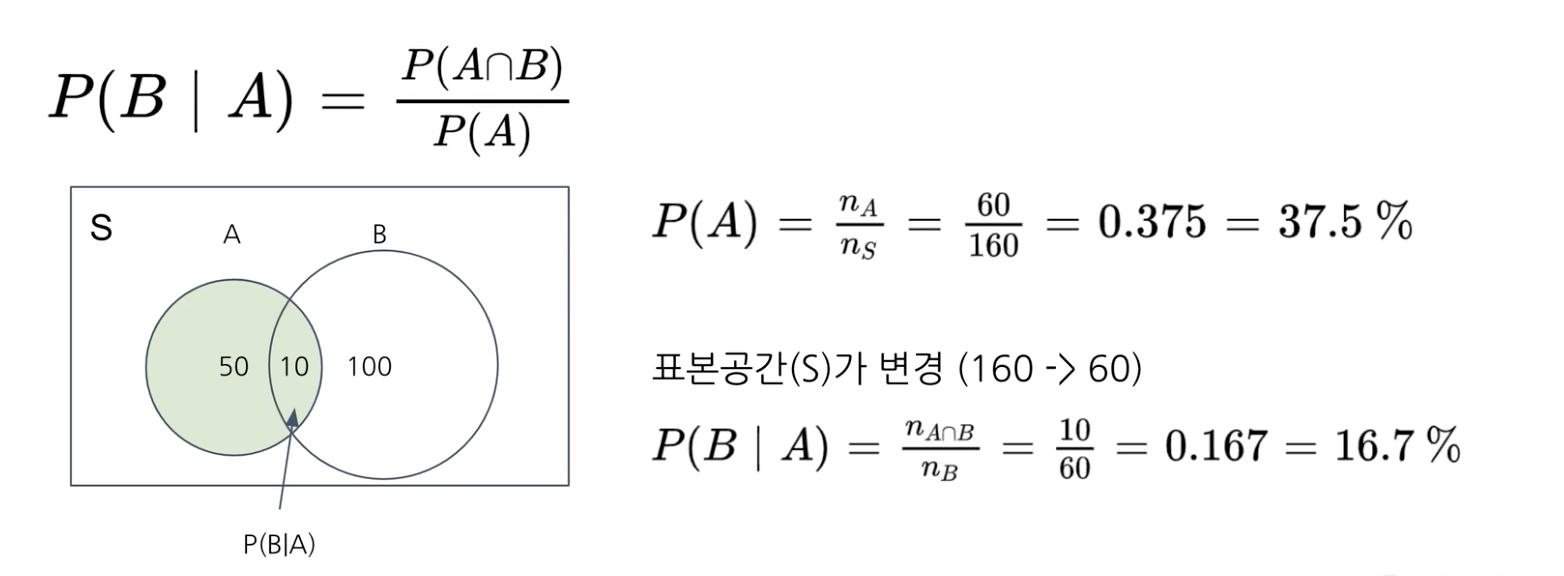
3) 조건부 확률
A 사건이 발생한 이후, B가 발생 할 확률
(추가 조건이 있어서 표본공간이 바뀐다.)
ex. 동전 2번 던졌을 때 모두 앞면이 나오는 확률
표본공간 4가지 관심 사건 1가지 -> 1/4
ex. 동전 하나는 이미 앞면이라고 알고 있는 경우 모두 앞면이 나오는 확률
표본공간 3가지 관심 사건 1가지 -> 1/3
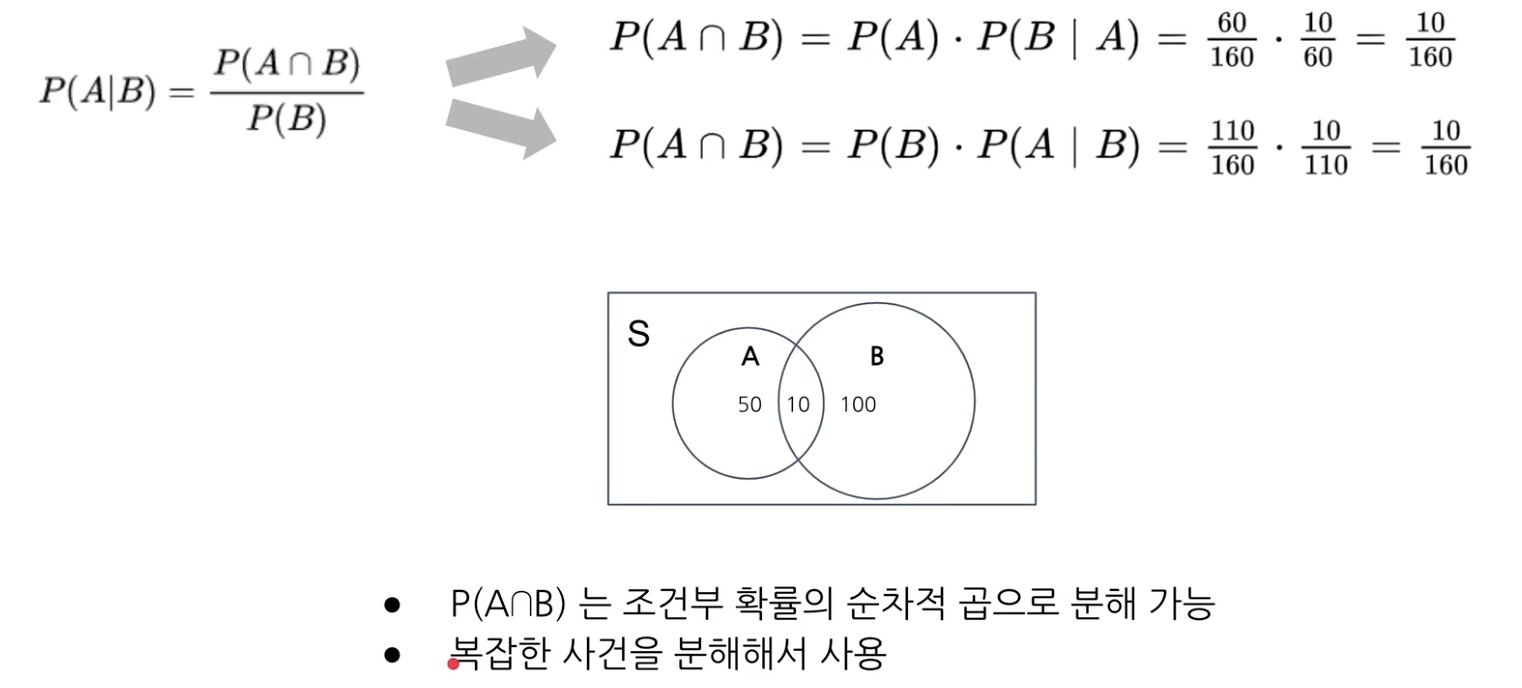
이처럼 조건부 확률의 순차적 곱으로 분해 가능하다. -> 복잡한 사건을 분해할 수 있다.
실제 예시


Exact bayes classifier: 조건을 모두 만족하는 경우를 찾아야 확률을 구할 수 있다. 정확히 일치하는 데이터가 존재해야 확률 구할 수 있다.
베이즈 정리
사전 확률과 사후 확률 사이의 관계를 조건부 확률을 이용해 계산하는 확률 이론
다시 말해서, 두 확률 번수의 사전 확률과 사후 확률 사이의 관계를 나타내는 정리다.
사전 확률 prior probability: 결과가 나타나기 전에 원인이 발생할 확률
우도 likelihood probability: 원인이 발생환 후, 결과가 나타날 확률 P(B|A)
위와 같이 주어진 정보인 사전 확률과 우도로 사후 확률을 계산할 수 있다.
사후 확률 posterior probability: 결과가 나온 이후 원인일 확률, P(A|B)
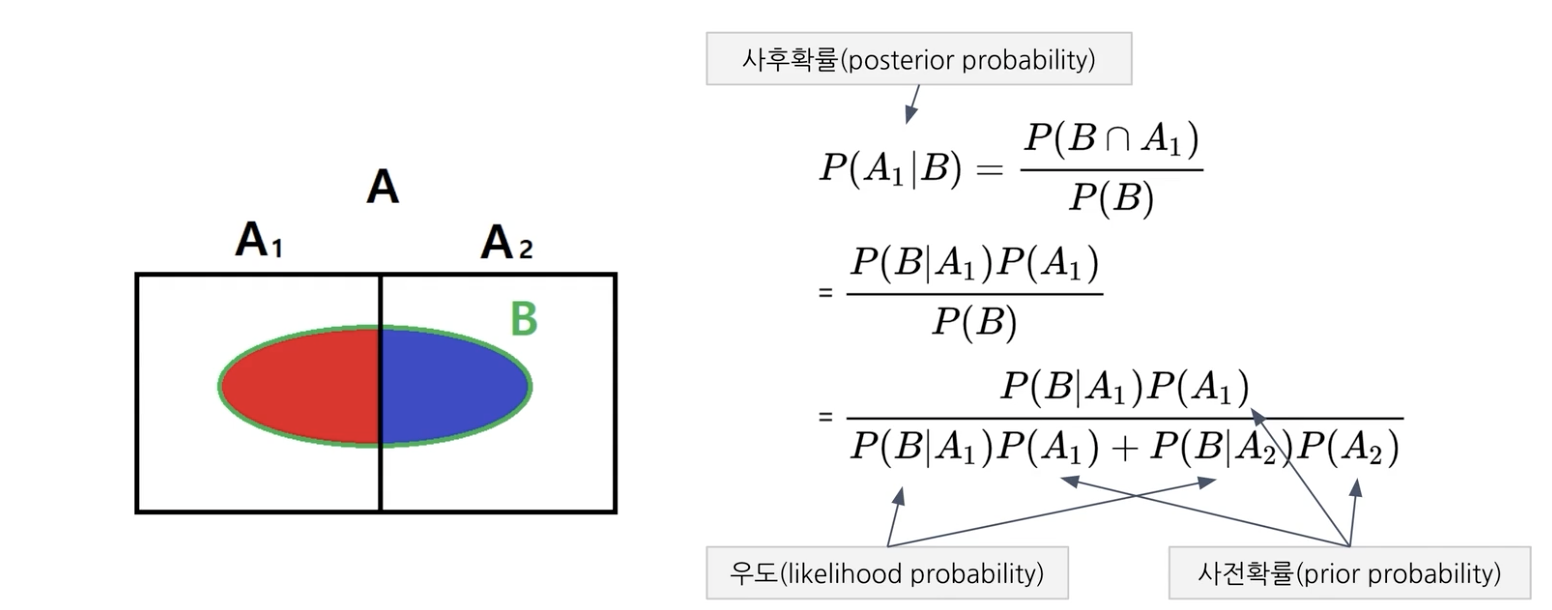
P(B) = P(B, A1) + P(B, A2) = P(B|A1) * P(A1) + P(B|A2) * P(A2)
naive bayes classifier: 앞서 배운 베이즈 정리(우도와 사전확률로 사후확률을 계산하는 정리)에 의해 분류하려난 대상의 각 확률을 나이브(특성을 독립이란 가정하에)(전문적이지 않게)하게 측정한다.
특성들 사이의 독립을 가정하는 베이즈 정리
독립변수가 많을 때 간단히 계산한다.
독립을 가정하는 것이 현실적 가정은 아니지만 연산의 복잡성을 낮춰주었다.
독립 가정 -> 정확히 일치하는 데이터가 없어도 전체 데이터를 이용해 계산한다. 왜?
P(X1, X2, X3, ... , Xn | Y = yk) = P(X1 | Y = yk) * P(X2 | Y = yk) * P(X3 | Y = yk) * ... * P(Xn | Y = yk)
앞의 경우에는 조건에 부합하는 케이스가 없으면 확률을 구할 수 없지만 독립으로 가정하면 모든 조건을 나눌 수 있기때문에 이와 같이 정확히 일치하는 데이터가 없어도 구할 수 있다. 이를 통해 연산이 단순해지고 직관적으로 변한다.
따라서 정밀도를 낮추고 연산의 편리성을 높인것이 이 분류기다.
exact bayes classifier의 경우, 정확히 일치하는 likelihood probability(모든 조건을 만족하는 케이스)가 존재해야 계산이 가능하다.

실제 예시

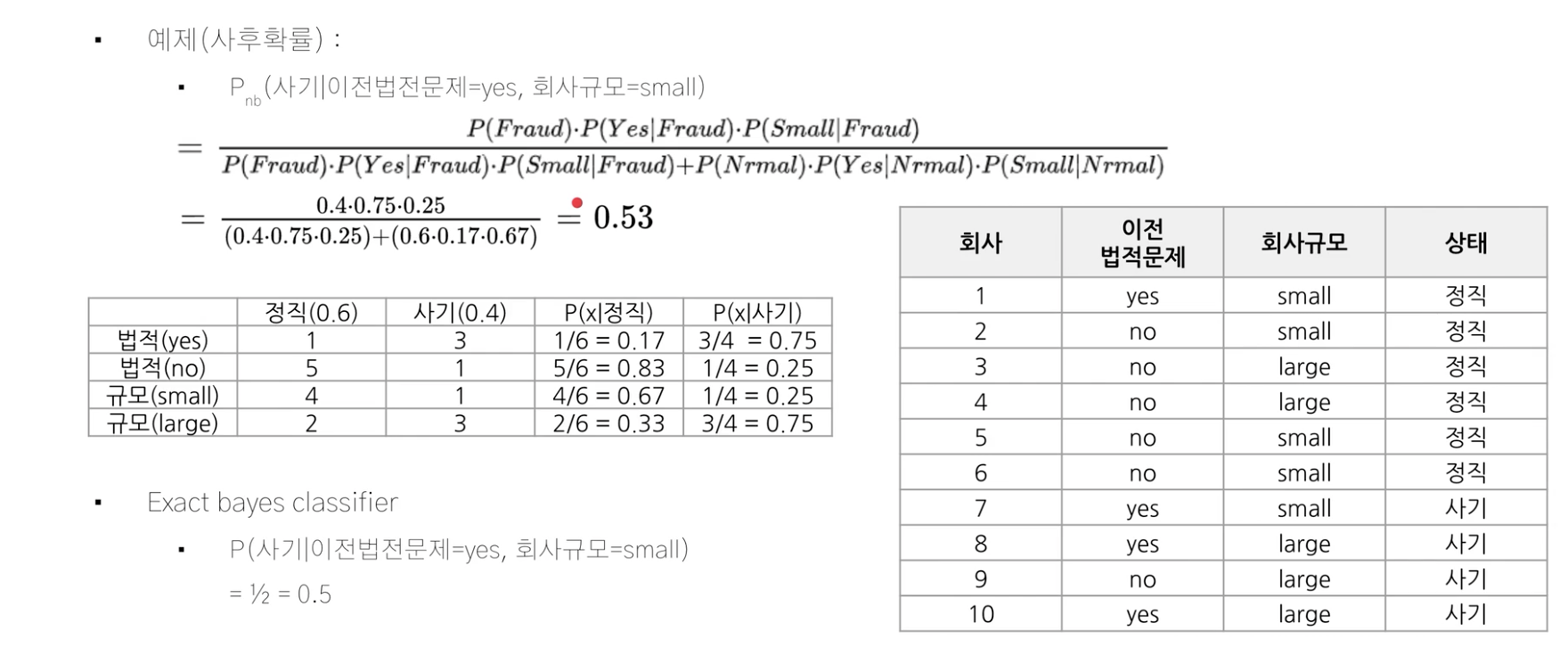
약간의 차이가 있지만 괜찮은 결과가 나타났다. 따라서 정밀도를 낮추고 연산의 편리성을 높인것이 이 분류기다.


구하고자 하는 것의 likelihood를 계산하고 이를 곱으로 변환하면 naive bayes classifier을 이용할 수 있다.
1장점
범주형 처리 0, 수치형 처리x
단순, 계산 효율
좋은 분류 성능
2단점
성능을 위해서는 많은 데이터 필요
값 0인 경우 확률이 0이 나와서 이를 처리: laplace smoothing (?)

확률이 하나라도 0(기존에 없는 새로운 단어가 입력)이 나오면 전부 0이 되니깐 이를 방지하기 위해서 분모나 분자에 상수를 더한다.
3개선
log 이용 언더 플로우 방지
확률을 계속 곱하다보면 숫자가 계속 작아져서 계산할 수 없는 범위로 작아지는 것을 underflow라고 한다.
이때, log의 성질을 이용해서 곱셈을 덧셈으로 변환하여 방지

근데 사실 이렇게 해도 log를 계속 더하면 음의 무한대로 빠지고 거기에 exp를 추가하면 0과 매우 가까워지므로 여기에 log-sum-exp trick을 사용해야한다.
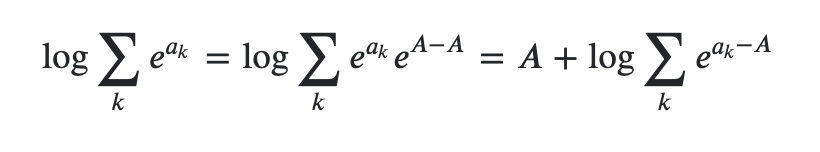
참고
Example of how the log-sum-exp trick works in Naive Bayes
I have read about the log-sum-exp trick in many places (e.g. here, and here) but have never seen an example of how it is applied specifically to the Naive Bayes classifier (e.g. with discrete featu...
stats.stackexchange.com
https://www.xarg.org/2016/06/the-log-sum-exp-trick-in-machine-learning/
The log-sum-exp trick in Machine Learning • Computer Science and Machine Learning
June 22nd, 2016. It is commonly not taught explicitly, but in machine learning you quite often come across problems which contain the following quantity and knowing the trick can help a lot. Let's say we have an \(n\)-dimensional vector and want to calcula
www.xarg.org
https://www.youtube.com/watch?v=-RVM21Voo7Q
9강 감정분석
극성(긍정, 부정 등)을 감지하는 텍스트 분석 방법
온라인 리뷰를 중요시하는만ㅋ므 중요한 분석이다.
1)필요성
대량 데이ㅓㅌ, 추출일관성, 실시간분석
2) 종류
1. Emotion detection
감정 사전 기반 or 머신/딥러닝 사용.
문맥이해의 어려움
미치도록 좋다 -> 부정 긍정으로 중립으로 판단할 수도 있다.
2. aspect based sentiment analysis
term을 기준으로 감정분석
3)활용
1.소셜 미디어, 브랜드, voc( voice of customer )을 모니터링하며
반응
잠재 고객 감정 감지,
2. 브랜드 모니터링
3.voc
4)방법
1) dictionary-based approach
단순하게 사전에 긍, 부정을 매핑하여 문서의 감성을 분석하는 방법
- 어려움:
사전의 질에 따라서 성능이 나뉜다.
문맥에 따른 감정분서이 어려움
-> n-gram 사용 (문맥 포함 사전 생성)
-> sequence 처리 딥러닝 ( rnn, transformer, bert 등 )
general 사전 적용이 어려움 도메인 별로 용어와 긍부정이 다르다 (ex. 상승은 일반적으로 긍정이지만, 물가상승은 부정으로 여겨질 수 있다.)
한글의 경우 감정 사전이 부족 (직접 구축)

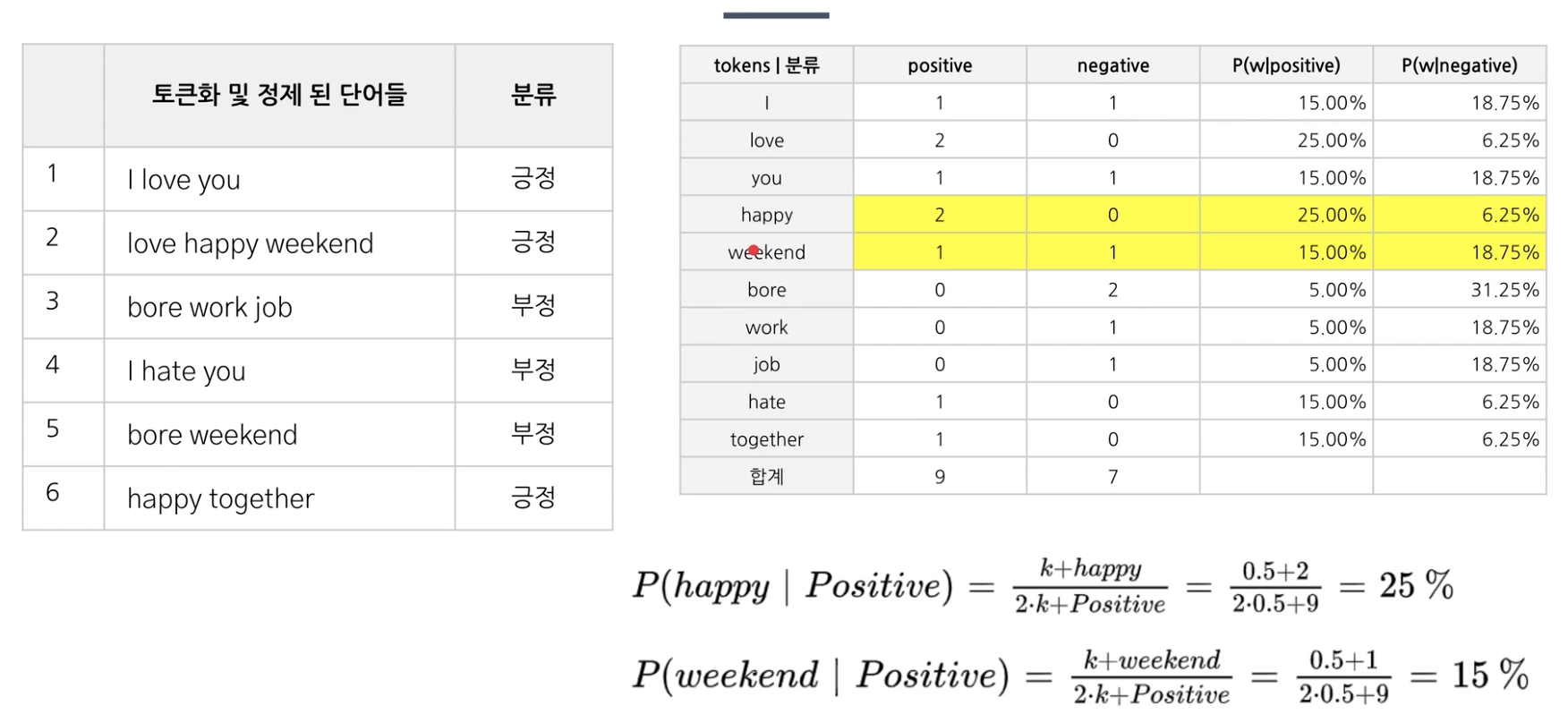
2) naive bayes classifier
감정 라벨된 학습데이터만 있으면 된다.

실무에서는 따로 도메인마다 학습데이터를 구축해야한다.
실제 예시



( w1 = happy, w2 = weekend )
즉, 단어마다 긍정인지 부정인지 확률을 알 수 있다면 위와 같이 문장에 대해서 긍정인지 부정인지 확률을 naive bayes 정리를 통해 알 수 있다.
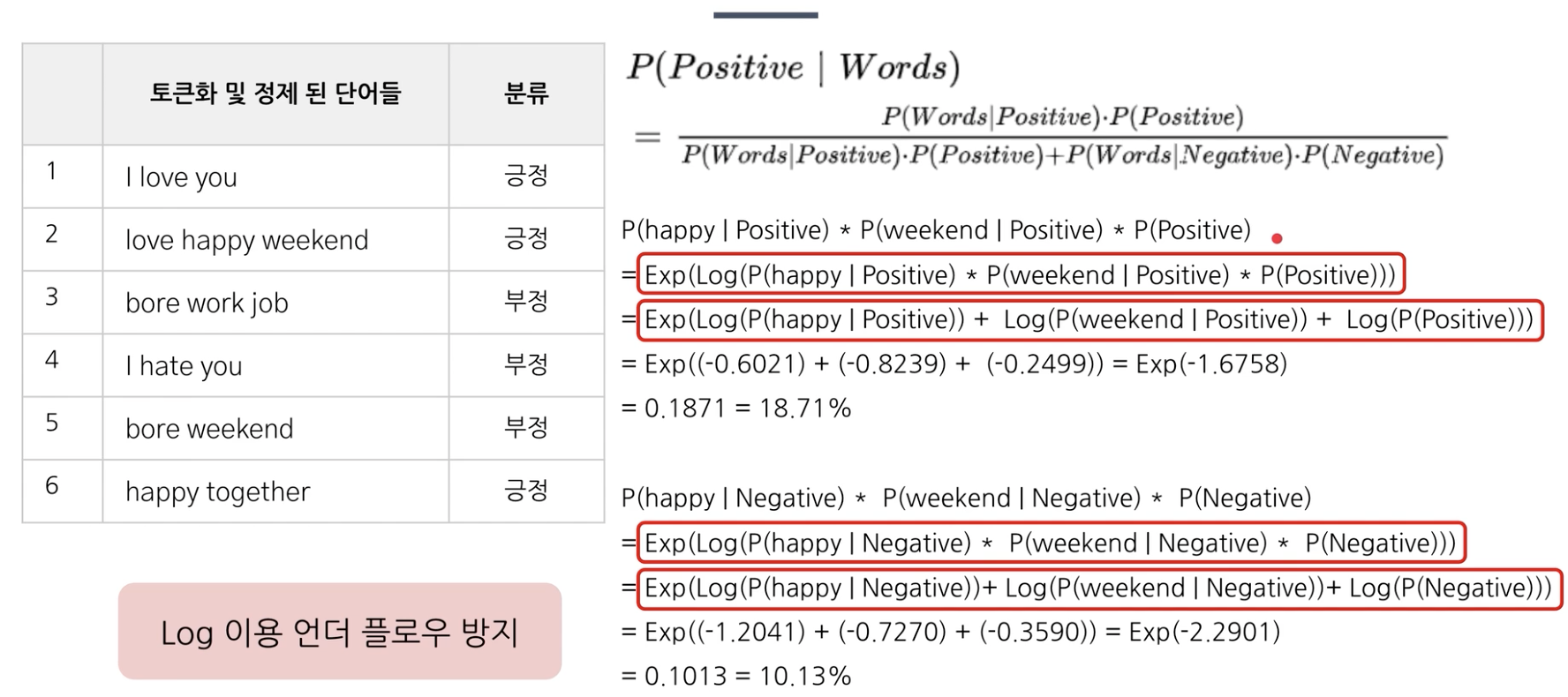

즉, happy weeked는 긍정이라고 예측할 것이다.
10강 word2vec & glove
word representations in vector space made by google
word2vec -> transformer -> bert
WORD2VEC
abstract
단어의 연속적 벡터 표현의 2가지 모델 cbow, n-gram을 제시한다.
단어 유사성으로 이 벡터 표현의 질을 측정한다.
이전의 방법보다 더 적은 비용으로 높은 성능을 보였다.
Introduction
원핫인코딩은 단어의 유사성은 고려하지 않는다는 단점이 존재한다.
그러나 단순한 모델에 대량의 데이터를 사용하는 것이 복잡한 모델에 적은 데이터를 사용하는 것보다 좋았다.
최근에 복잡한 모델에 대량의 데이터를 사용하는 것이 가능해지면서 성능이 개선되었다.
=> 단어의 distributed representation을 사용한다.
goals of the paper
대량의 단어 데이터로부터 좋은 품질의 벡터를 학습할 수 있는 word2vec을 소개한다.
유사한 단어 간에는 거리가 가까운 경향이 있다.
게다가, 단어가 다양한 유사도를 가진다. ( 예를 들어서, king - man + woman = queen )
의미 보존

accuracy 측정 방법
kings - king + queen에서 queens가 나오는지로 확인한다.
단어벡터끼리 빼고 더해서 특정 단어벡터가 나오는 지 확인한다.
문서를 벡터화할 수 있을 때 서로간의 유사성만 파악할 수 있었다면 이제는 의미적인 부분까지 파악할 수 있게 됐다.
model architecture
LSA보다 나은 선형 정규성 linear regularity: 앞선 의미보존에서 본 것처럼 산술 연산을 통해서 벡터를 추론할 수 있다.
LDA보다 나은 연산 효율성: 데이터 양이 많을 수록 더 많은 연산 필요
모델 복잡도 O = E * T * Q
(E는 number of epochs, T는 number of words in trainset, Q는 모델 별도 설정 )
*LSA, LDA
LSA:
LDA:
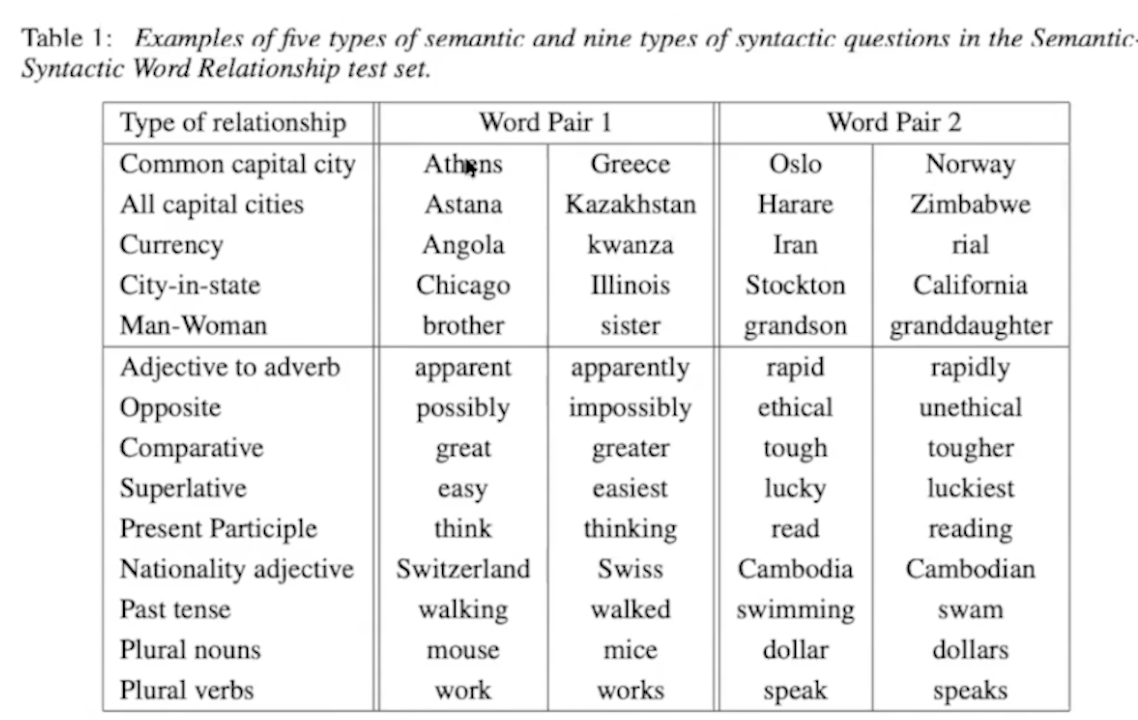
1) C-BOW 주변부 중심단어
w(t-2) w(t-1) w(t) w(t + 1) w(t + 2)
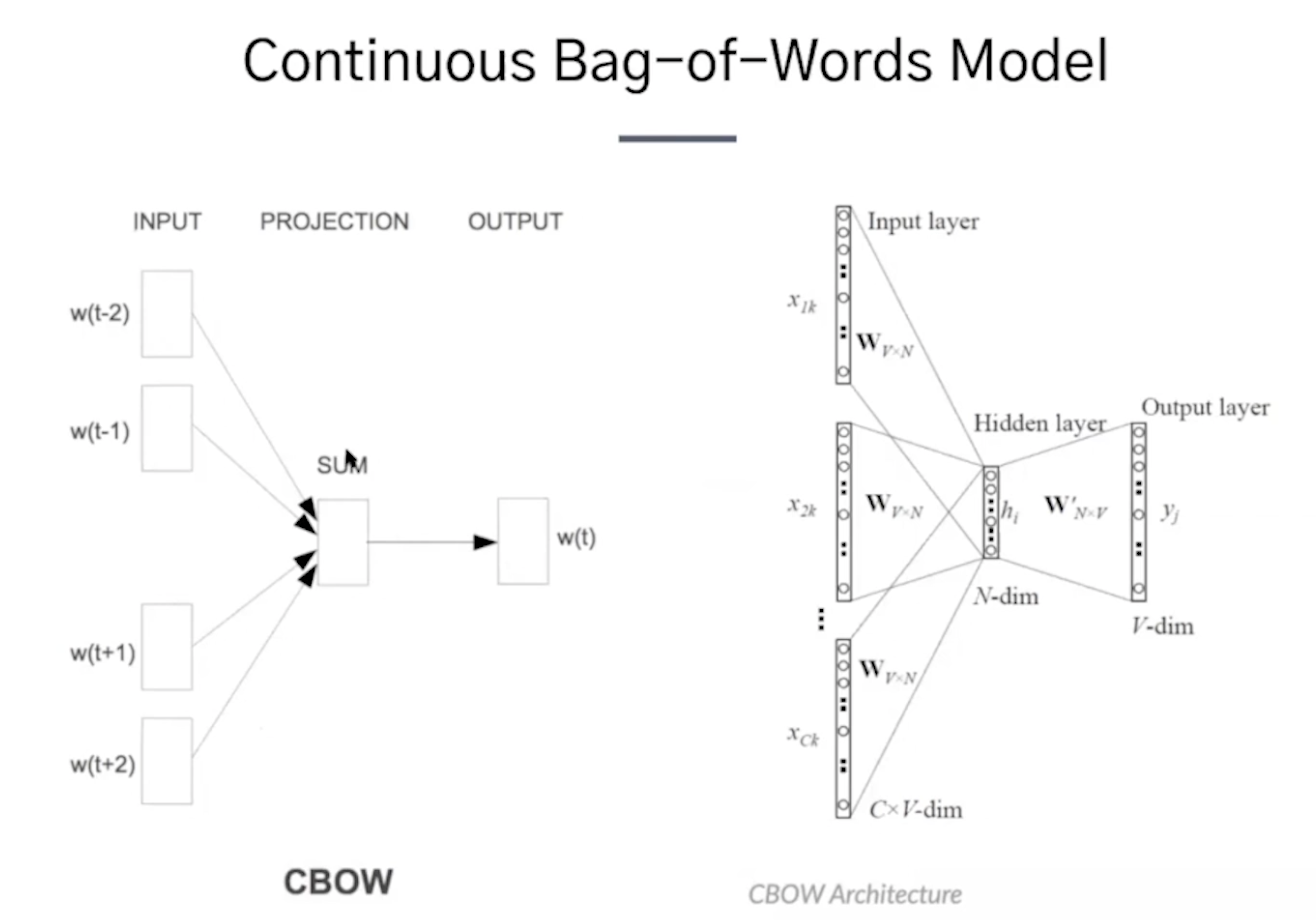

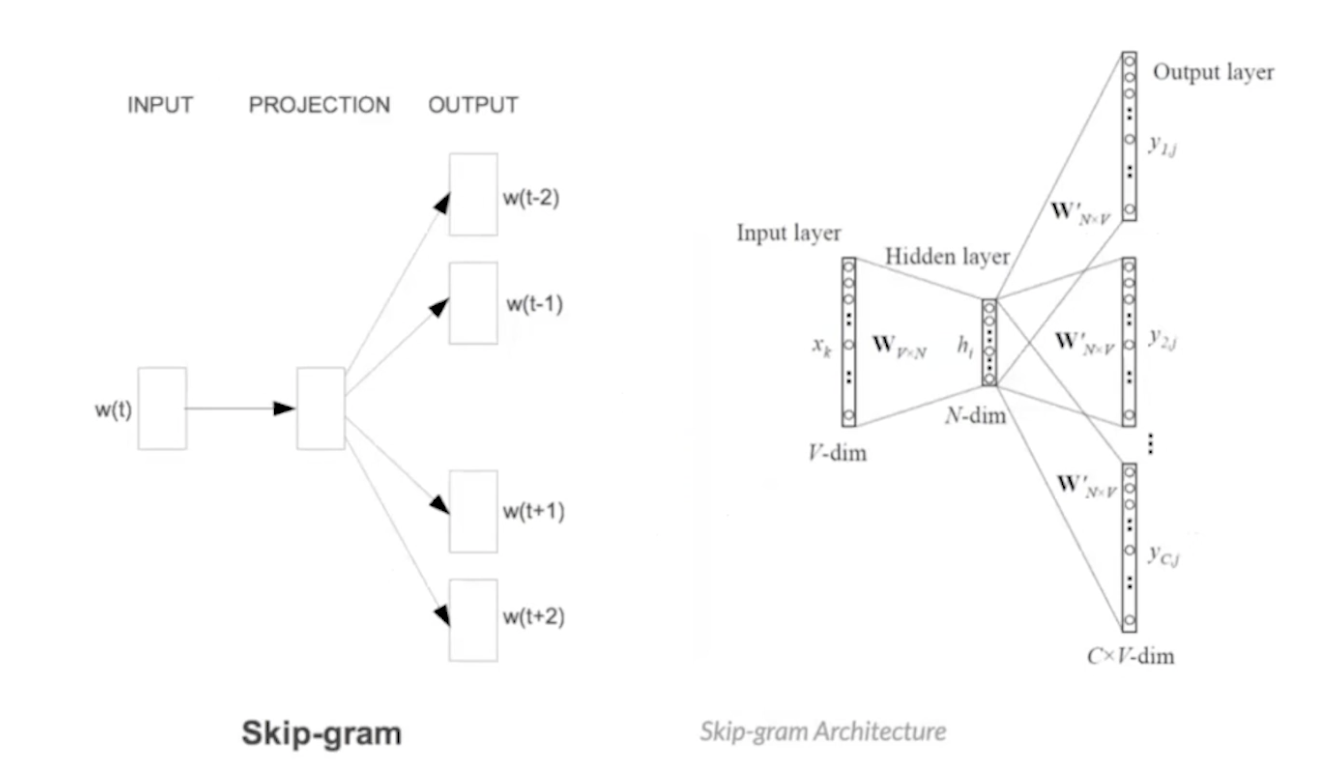
2) Skip-gram 중심단어 주변부
conclusion
정리하자면 간단한 모델 구조로 대량의 단어 데이터로부터 좋은 품질의 벡터를 만들어냈다.
연산 복잡도도 낮으며 높은 정확도를 보였다. 벡터 표현력이 증가해서 nlp 활용부분에서 성능을 개선시킨다.
특히, skip gram이 어려운 task를 해결하기때문에 성능이 더 좋았다.
실제 구현해보기
1. 원핫인코딩은 sparse -> dense vector로 바꿔보자
2. 원핫인코딩에서 단어간의 유사성을 표현할 수 있도록 바꿔보자.
구현1.
사용하지 않는 품사를 제거해서 입력 문장 토큰화
원핫인코딩
학습

가중치가 단어벡터가 된다.


이렇게 하면 어떤 단어와 유사성이 높은지 알 수 있다.
그래서 유사도가 높은 단어 벡터를 알 수 있다.
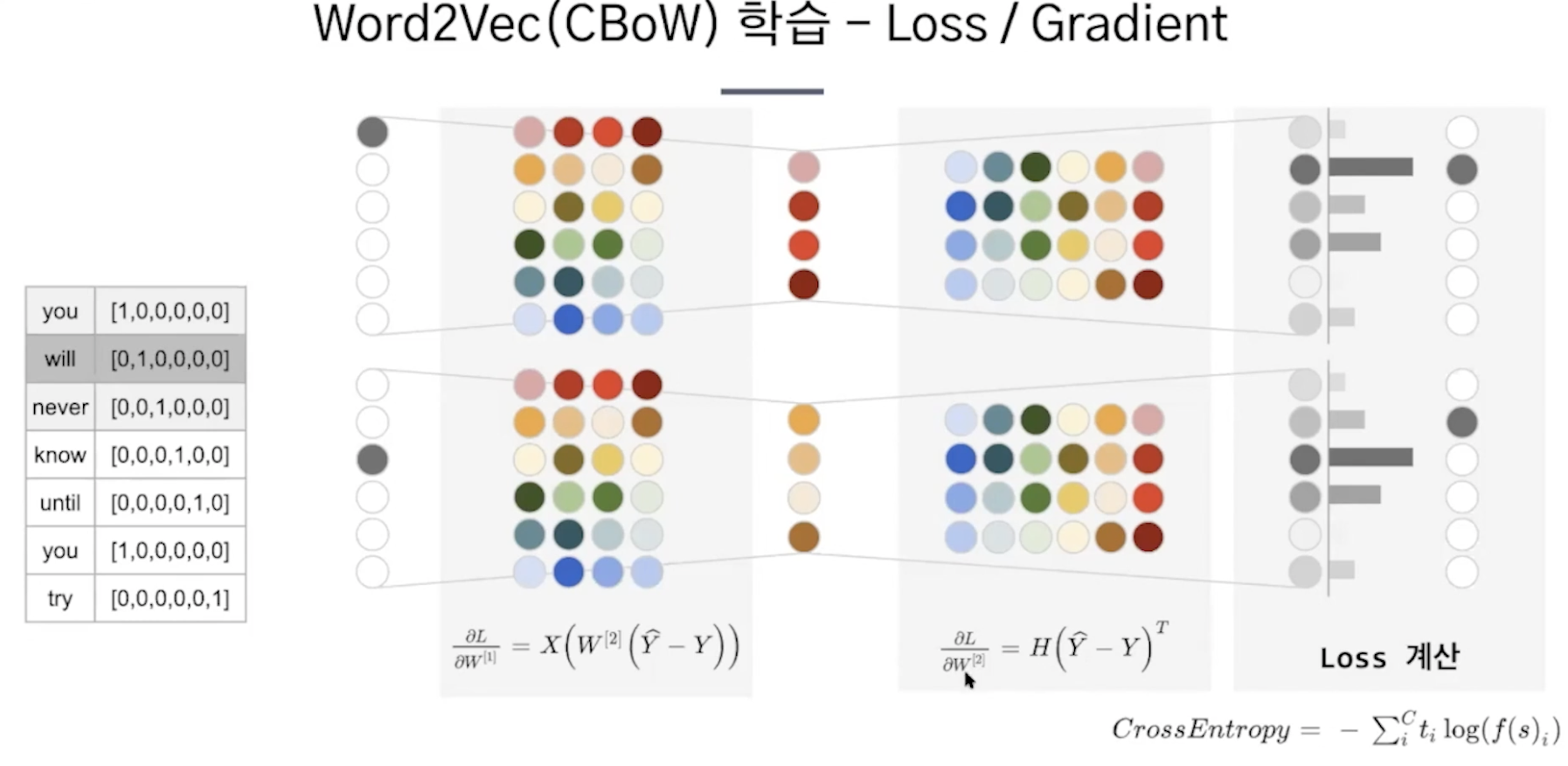
cross entropy는 multi classification 다중 클래스에서 로스를 구해준다.

구현2. 대용량 처리
위의 구현 방법에서 2가지 측면을 개선할 수 있다.
하나는 어차피 가중치에서 해당 벡터를 가져오는 것이기때문에 굳이 원핫벡터를 만들어서 메모리와 연산을 낭비할 필요없다.
단어수가 100만개라고 생각해보면 너무 많다.
다른 하나도 마찬가지인데 마지막에 계산을 할때 어차피 cross entropy에 넣으면 나머지는 다 0으로 처리되는데 굳이 계산할 필요가 없다. 필요한 것만 계산하자. ( 선택한 단어와 나머지 모든 단어간의 유사도를 구하는 것이다. )
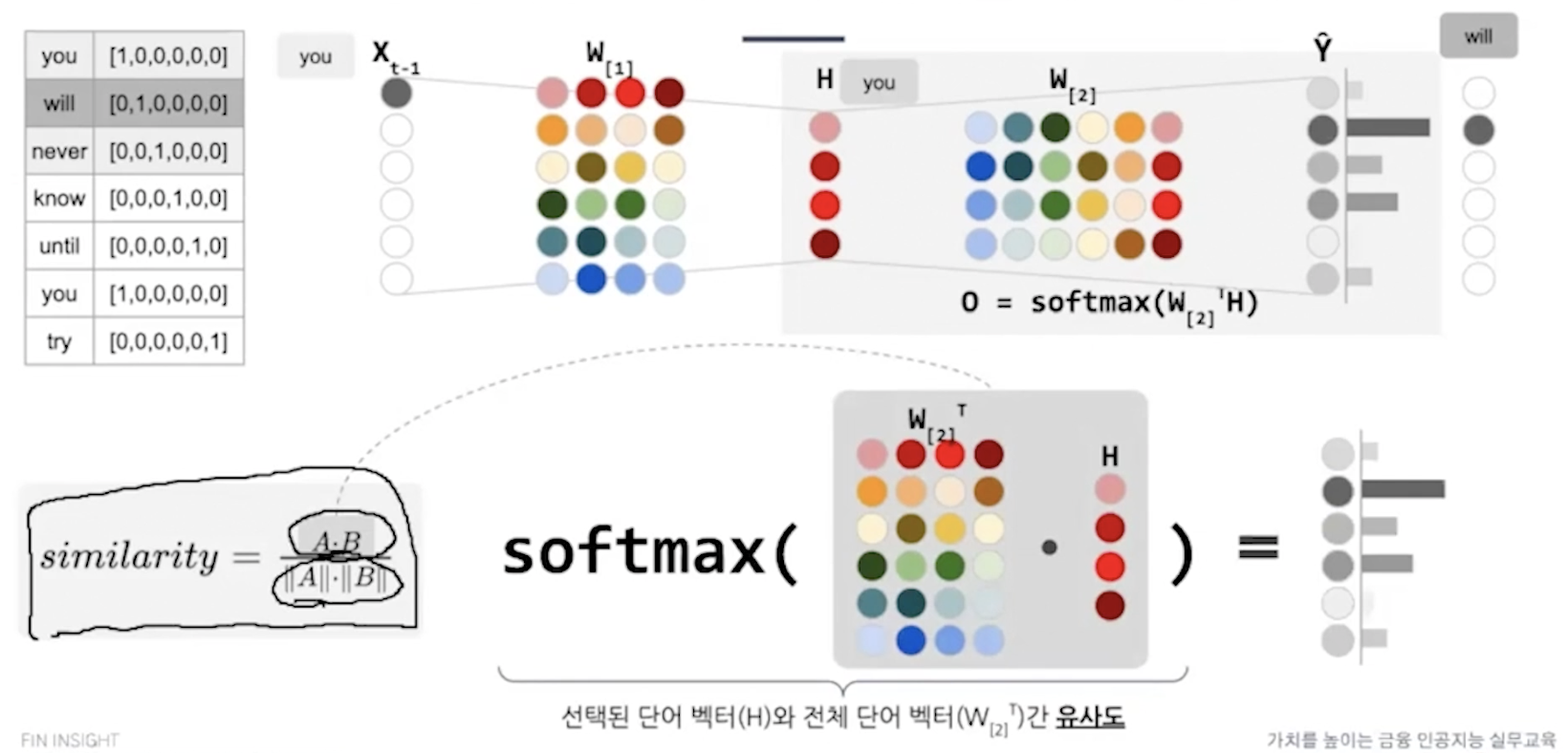

negative sampling, subsampling
입력 레이어를 없애고 그냥 가중치에서 뽑아쓰는 걸로 연산을 줄임
multiclassification(softmax) -> binary classification(sigmoid) 손실계산 비용을 줄였다.
맞추었나 못맞추었나 ( 문맥단어와 중심단어만 고려 )
정답만 맞추면 안되고 오답문제도 풀어서 학습을 시켜야한다. 오답은 무엇을 고를거냐면
단어분포를 고려해서 빈도가 높은 단어를 오답을 많은 횟수로 학습, 적은 단어는 적은 횟수로 학습
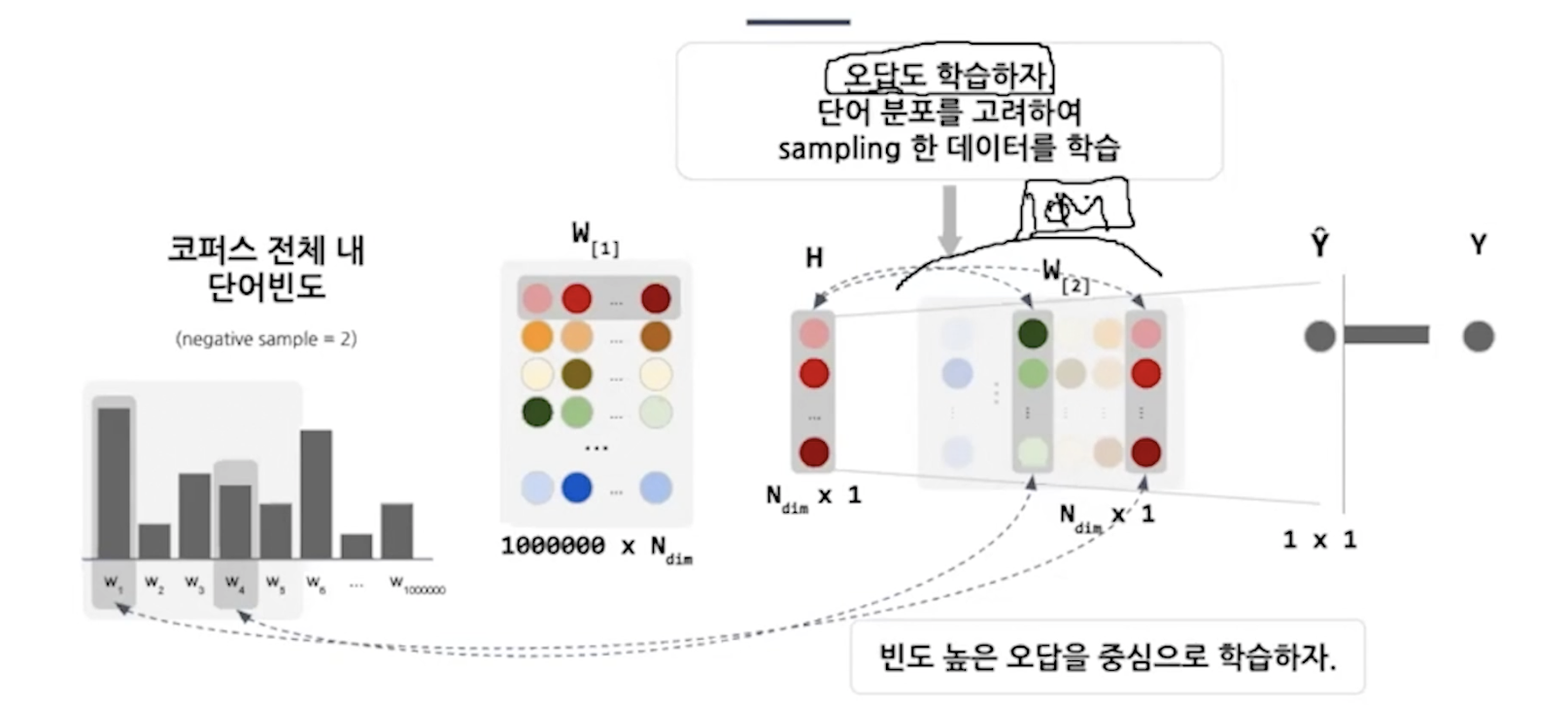
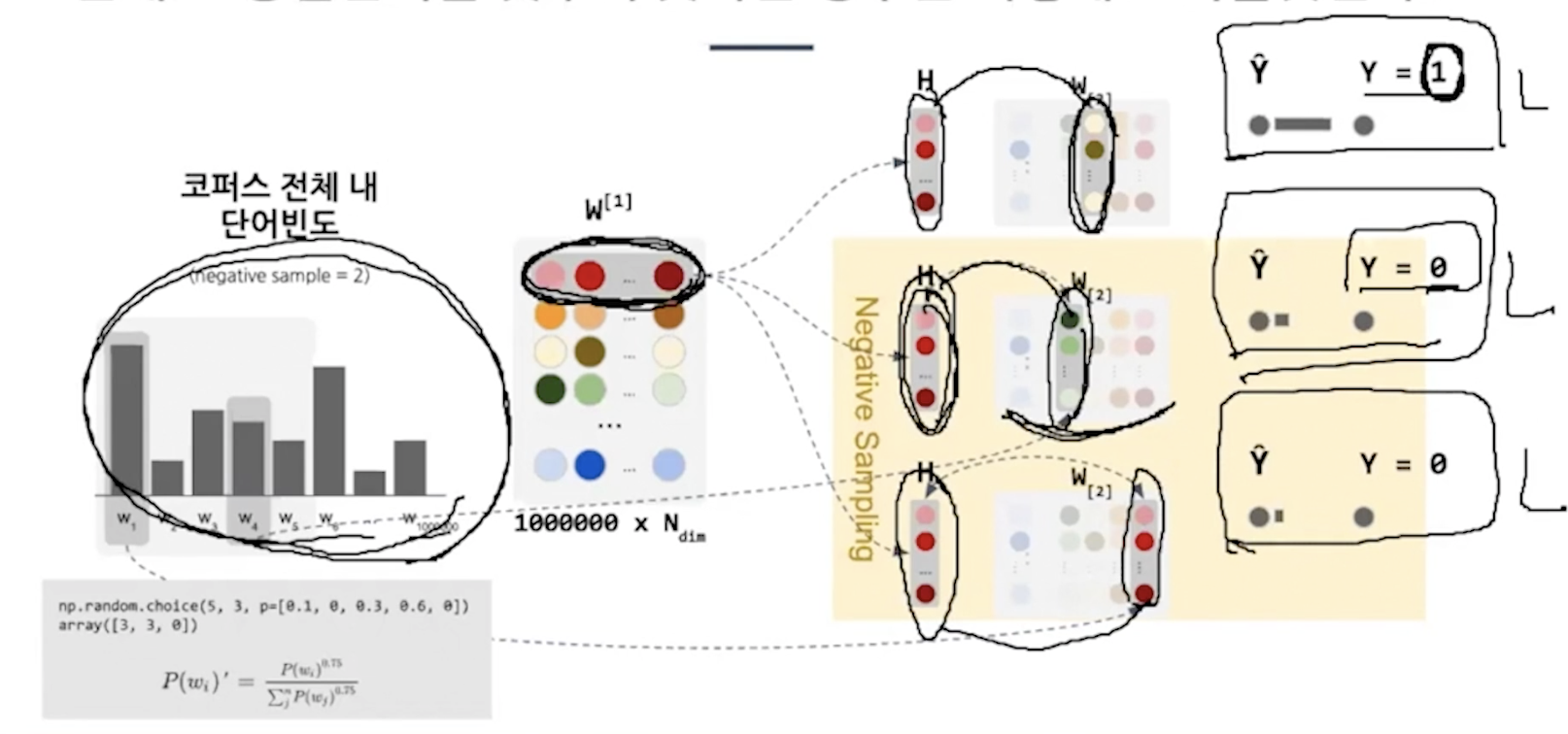
0.75를 제곱하는 이유? 자주 등장하는 단어의 영향력을 낮추고 적게 등장하는 단어의 영향력을 늘려준다.
총 5개에서 3개를 선택하는데 옆에 나온 확률을 기반으로 뽑는다.

기존 임베딩(LSA)의 단점.
단어에 대한 전체 통계정보를 활용하는데 단어 유추 문제에 좋지 않은 성능을 보임
기존 임베딩(word2vec)의 단점.
지역적인 문맥(Local context)로 단어 유추에서 좋은 성능을 보이는데 통계정보를 활용하지 않는다.
그래서 glove는 두 개의 장점을 취했다.
global vectors for word representation
임베딩된 단어 벡터간 유추문제에서 좋은 성능을 보이면서 말뭉치 전체의 통계 정보를 반영하는 것이 목표다.
objective function == loss function

임베딩된 두 단어벡터의 내적이 말뭉치 전체에서의 동시 등장확률 로그값이 되도록 목적함수를 정의
윈도우와 행렬분해방식
이 예제를 보자.

여기서 solid는 steam보다 ice와 가까이 학습되는 것이 맞다. 그래서 이런 지표를 통해 학습할 수 있다.
lsa는 tdm같은걸만드는데
glove는 윈도우방식으로 단어-문맥 co-occurrence 행렬을 만들고 이를 분해하여 벡터로 사용한다.
[3fasttext]
지적: 자주 등장하지 않는 단어에 대해서 학습하기가 어렵다. 그래서 언어의 형태학적인 특성을 반영하지못하고 희소한 단어는 임베딩이 되지 않는다.
개선: bag of characters로 본다. 개별 단어가 아닌 characters를 임베딩한다.
하나의 단어 안에도 여러 단어들이 있는 것을 간주한다. 내부 단어를 고려하여 학습한다.
게다가 OOV out of vocabulary단어들에 대해서도 내부 단어를 통해 유사도를 구할 수 있다.
각 단어를 글자의 n-gram으로 나타낸다.
apple -> <ap app ppl ple le>
다른 단어에서 n-gram으로 birth, place를 학습한 적이 있다면 birthplace의 임베딩 벡터를 만들어낼 수 있다.
그래서 rare word를 n-gram을 통해 학습할 수 있다. 학습량이 훨씬 많아진다.
소셜텍스트처럼 노이즈가 많은 코퍼스에 강점을 보인다. 단어 자체가 아닌 문자별로 끊기 때문이다.
오타가 섞인 단어도 일정 수준의 성능을 보인다.
한국어의 경우,
글자 단위
자연어처리 -> <자연, 자연어, 연어처, 어처리, 처리>
자모 단위(초, 중, 종성 단위)
ㅈ ㅏ, ㅈ ㅏ _, ㅏ _ ㅇ, ... 중략

전체적으로 word embedding 방법론을 살펴보았다.


문맥을 고려하지 못한다.
11강 딥러닝 자연어 처리 모델 cnn
mlp 문제점
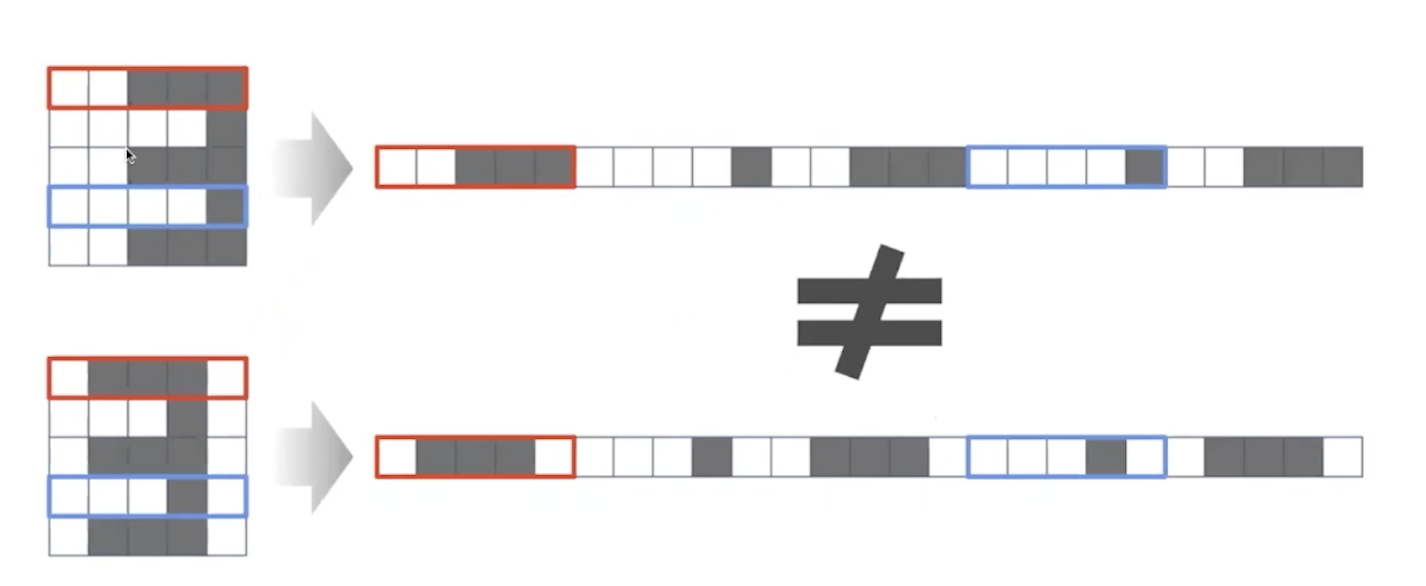
cnn for text classification
cnn for sentence classification 한국사람의 모델
문장을 단어로 나눠서 벡터로 표현한다. 필터가 행을 단위로 탐색한다. 이때 n-gram을 사용한다.
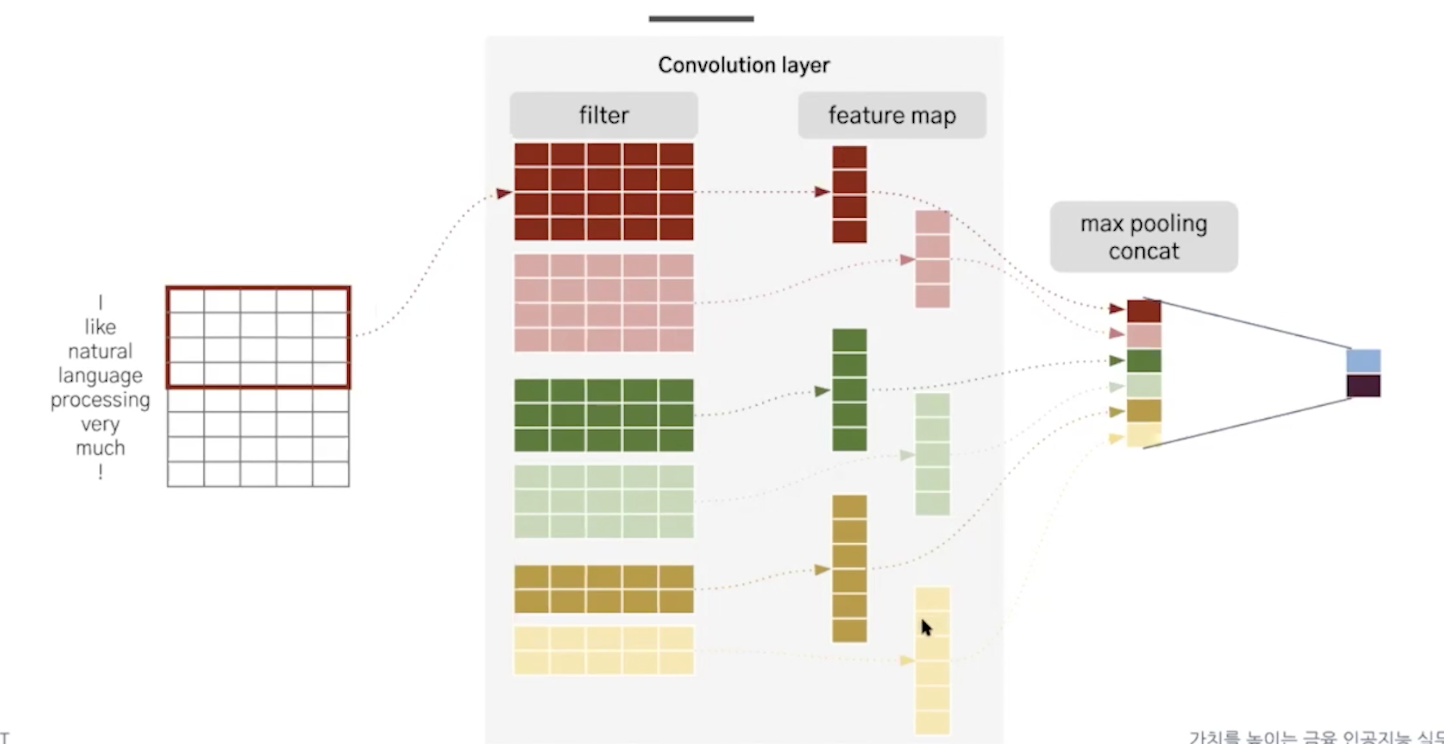
단어를 임베딩해서 벡터로 만들고 이를 필터를 통과시켜서 피쳐맵을 뽑고 풀링한 후 concat하고 dense layer에 통과시킨다.
filter의 종류가 많은 이유는 이것들이 모두 뉴런이고 다른 특징들을 추출해준다. 아래의 링크를 참고해보면 이해에 도움이 된다.
즉, mlp로 생각해보면 flatten input이 들어오면 다음 레이어의 여러 뉴런들(weight)가 feature extraction을 하는데 이를 cnn으로 확대해보면 input feature map이 들어와서 여러 뉴런들(filter)가 feature extraction을 하는 것이다. 이때 연산을 convolution라고 한다.
https://stackoverflow.com/questions/36243536/what-is-the-number-of-filter-in-cnn

중요한 것은 모델을 사용하고 성능도 개선할 수 있어야한다.
실제 구현
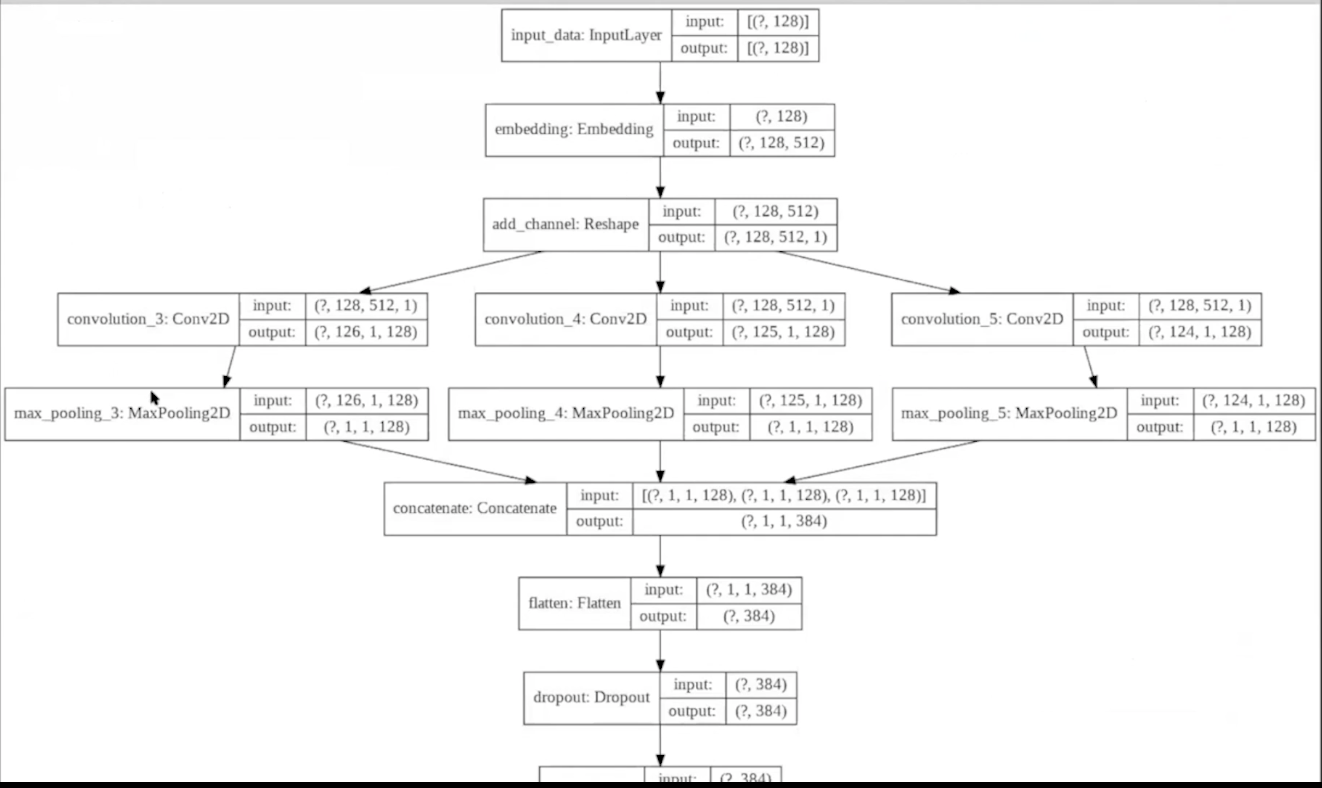

12강 rnn
1.rnn
시계열 데이터을 모델링할 수 있는 구조다. 문맥을 담을 수 있다.
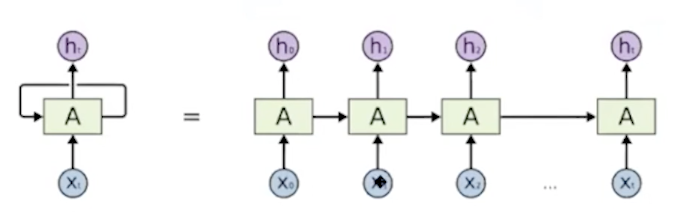
문장의 전체 정보를 담고 있는 하나의 벡터로 context vector가 마지막에 나온다.
이걸 가지고 task를 해결한다. transformer가 나오기 전에 자주 사용되었다.
활용
언어모델링 bert에서 다룬다.
기계번역 ( 구글 번역기, 파파고 ) -> 번역 전 번역 후를 학습데이터로 사용
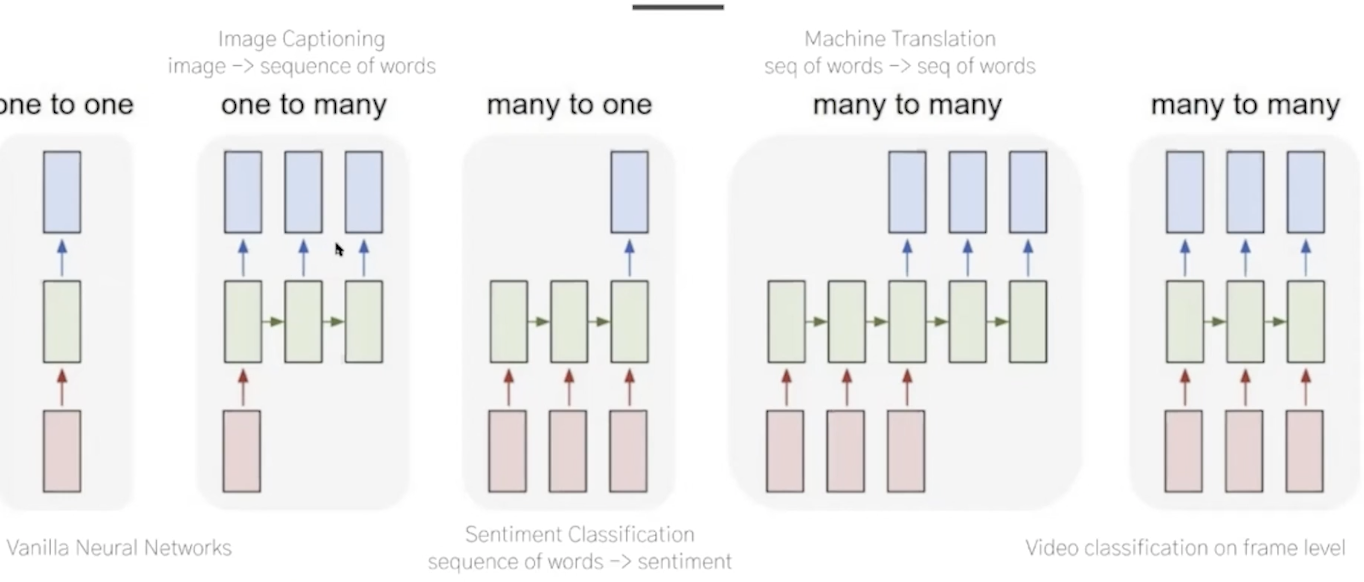
이미지 캡셔닝 Image captioning one to many
인풋: 이미지 벡터 -> 아웃풋: 설명 문구

감정분석 many to one
인풋: 문장 토큰화 -> 아웃풋: 감정

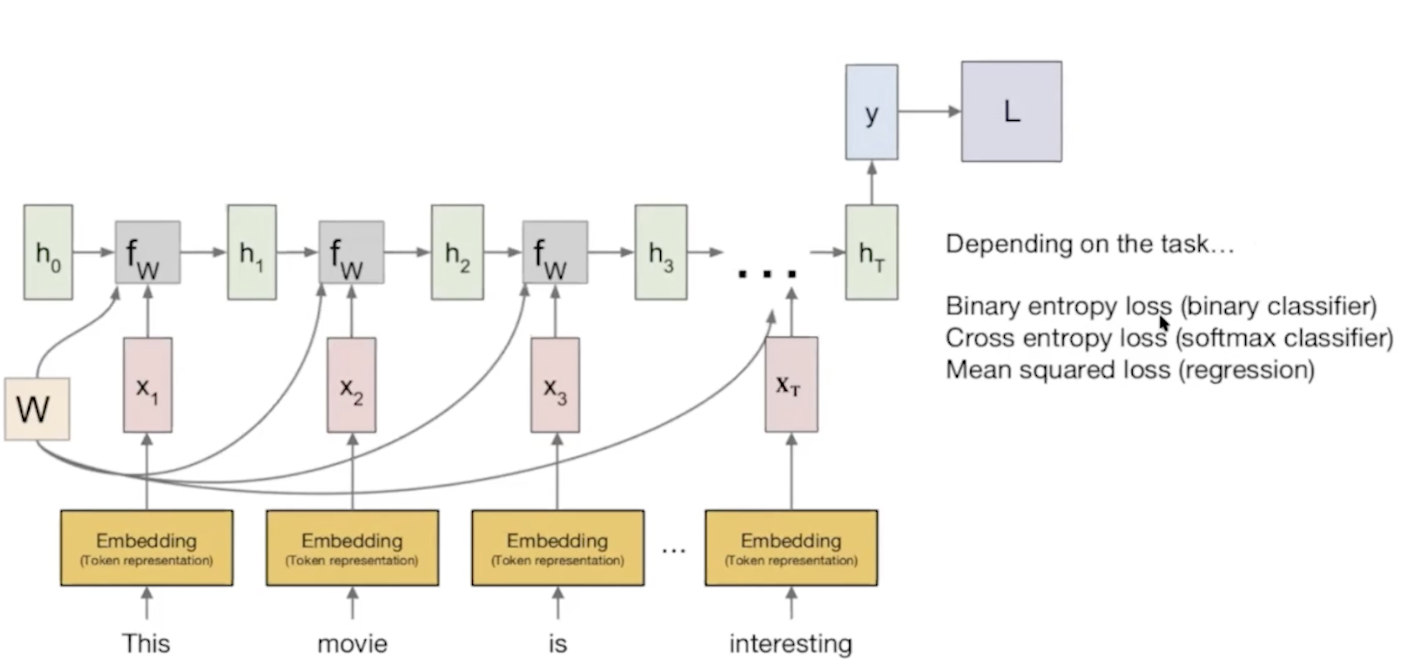
기계 번역 seq2seq
인풋: 번역 전 문장 -> context vector -> 아웃풋: 번역 후 문장
나중에 별도로 확인할 예정
비디오 분류, 품사태깅, 개체명 인식 many to many
프레임 -> 프레임 별 라벨링 차 사람 음식...
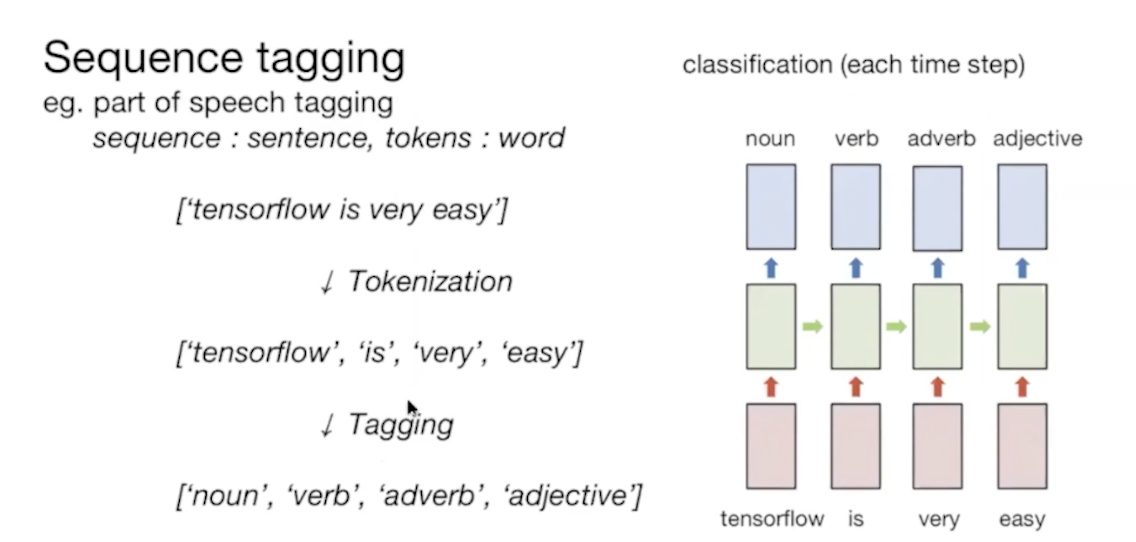
역시나 데이터를 어떻게 구축 해야하는가?
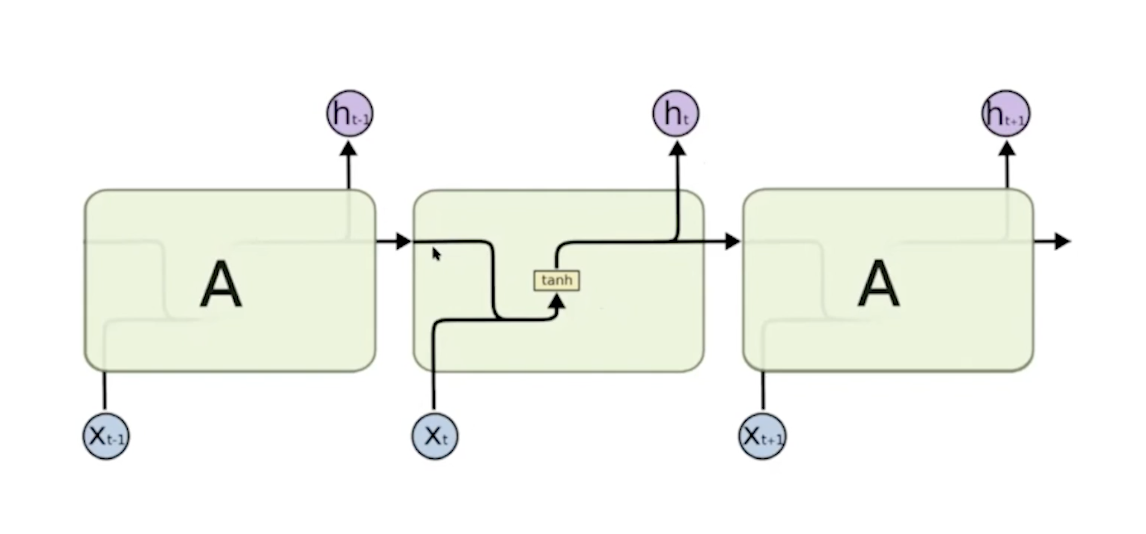


t+1 <- t, t-1이 반드시있어야해서 순차적으로 계산해야해서 느리다는 단점이 있다. 대신 이전 정보를 전부 기억할 수 있으니 장점이다.
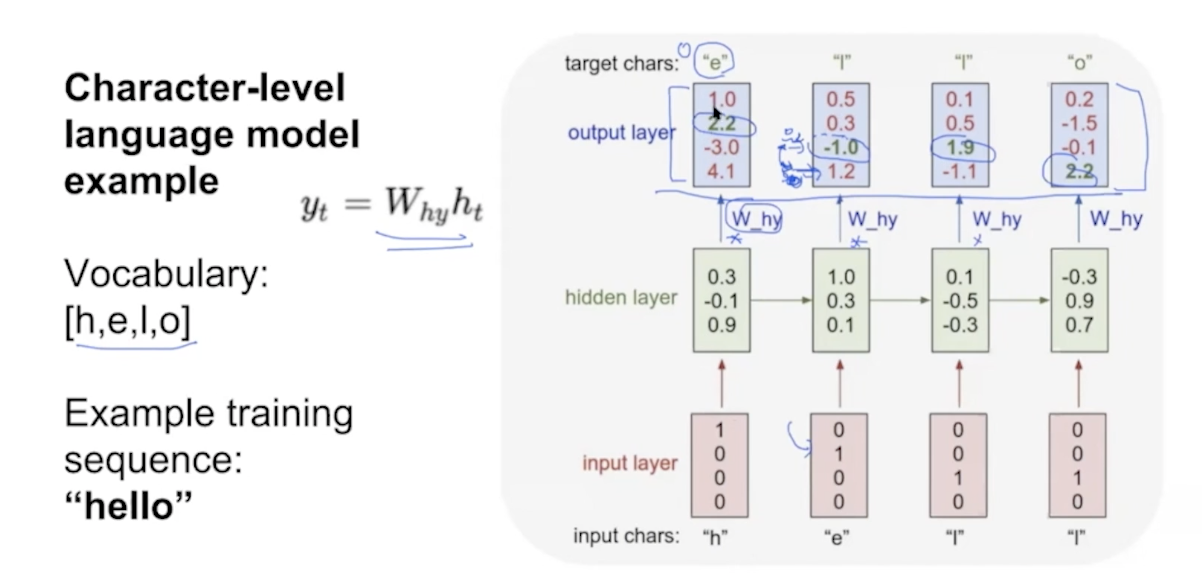
h -> e (0100)
he -> l (0010)
hel -> l (0010)
hell -> o
loss -> gradient -> update
*성능을 개선하는 두가지 방법: stacking, bidirectional
이후의 모델에서 이 두 방법을 차용하고 있다.
1)what is stacking?
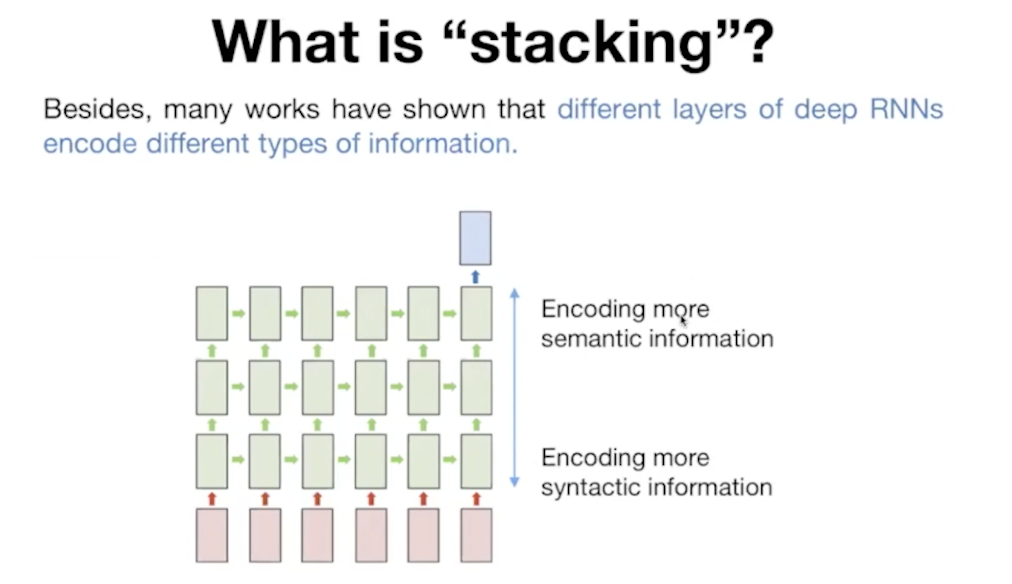
이 증명은 elvo에서 나중에 알려준다 일단 레이어를 늘리면 성능이 좋아진다.
1) many to many
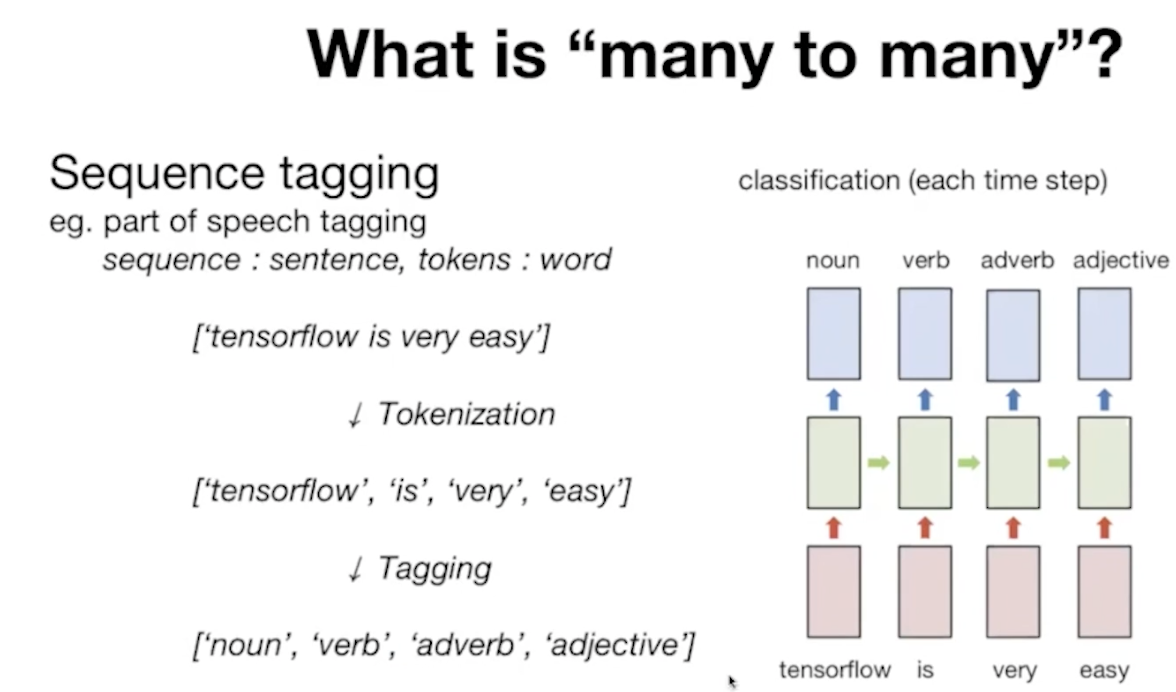
앞에 문맥(context)적인 부분이 포함돼서 성능이 향상된다.
2)bidirectional
양쪽으로 정보를 줘서 예측하도록 한다. 학습속도가 더 빨라진다. 왜?
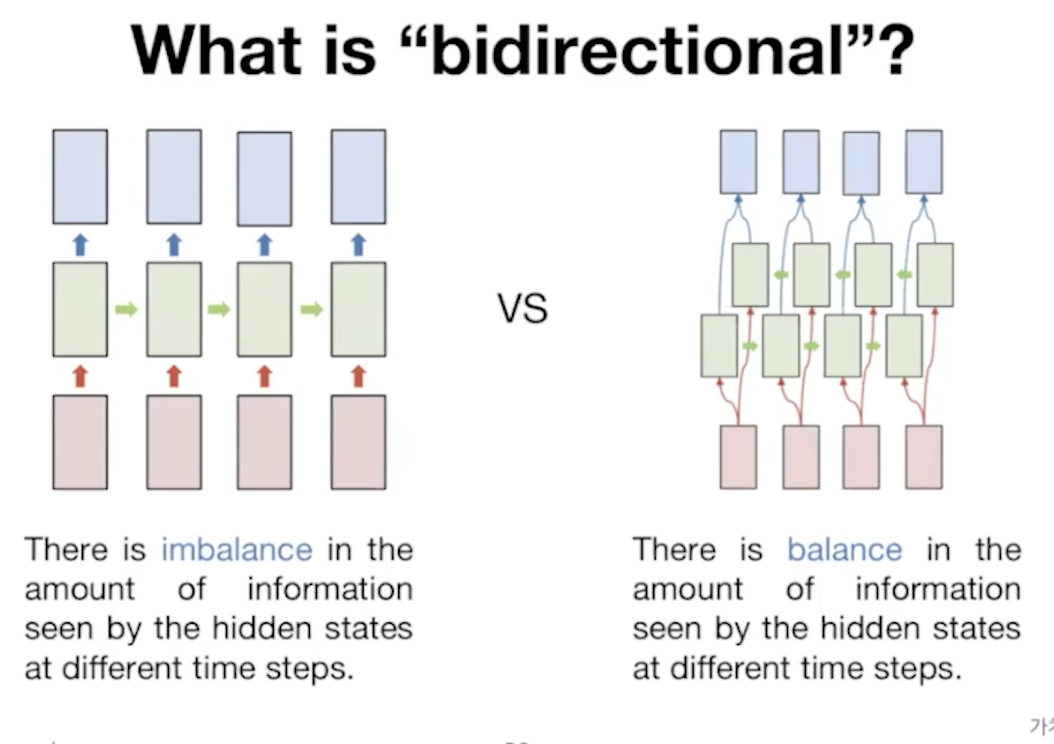
# tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64, return_sequences = True))
# tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32))
실제로는 이렇게 간단하게 표현할 수 있다.
2.lstm
long dependency 문제, gradient vanishing 문제
거리가 먼 곳에 있는 정보가 제대로 전달되지 않는다.
거리가 먼 곳의 정보를 장기적으로 기억을 끌고 가기 위해서 탄생했다.
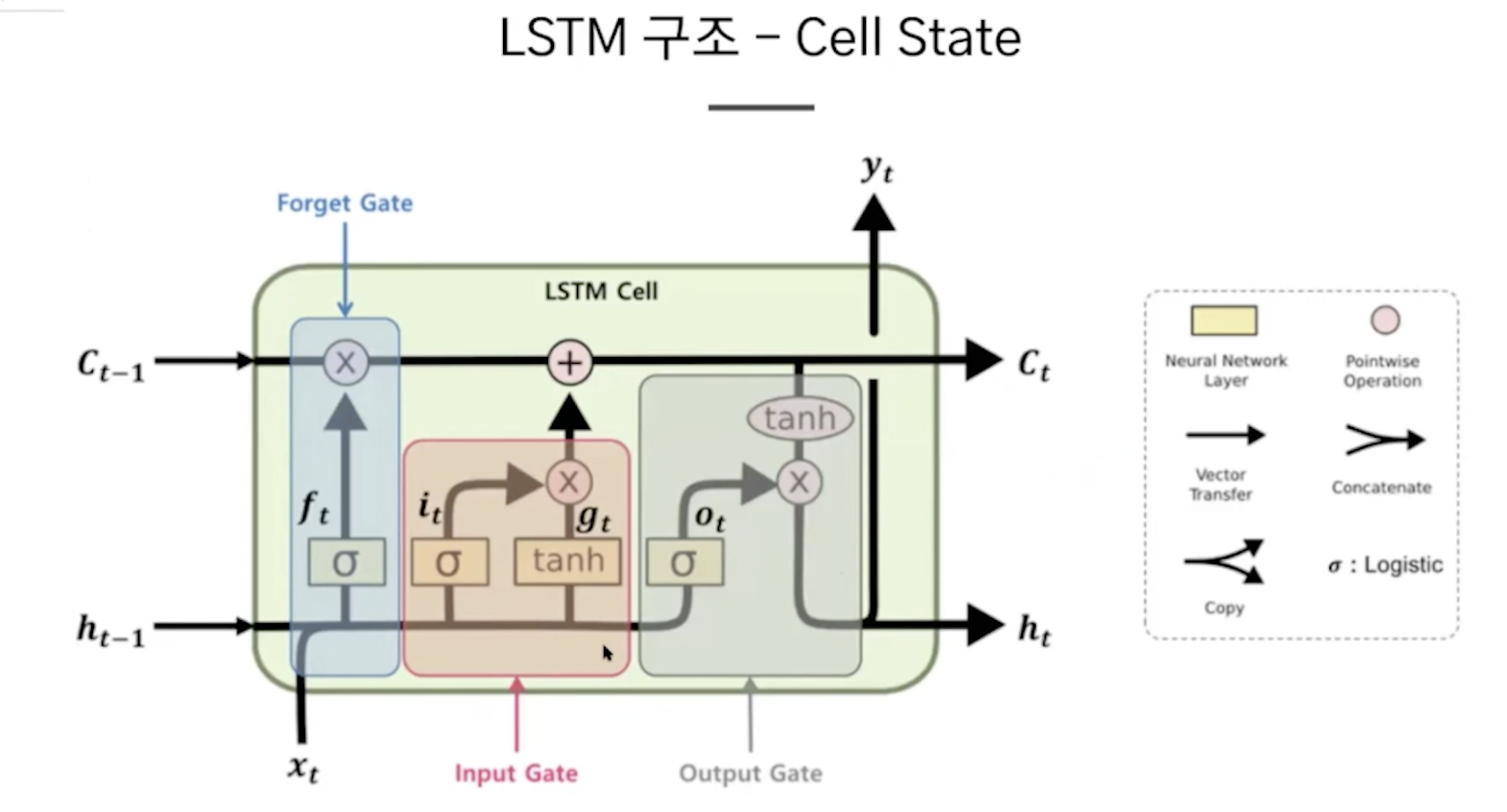
***cell state: 전체 네트워크를 아우르는 장기 이전 정보
forget gate: 얼마나 망각하여 가져갈지 0 -1로 결정한다.
input gate: tanh는 새로운 정보, sigmoid 새로운 정보를 얼마나 추가할지
- cell state에서 얼마나 유지할지,, ,현재 정보는 얼마나 더할지 정하고...
output gate: cell state를 tanh는 이전 정보, sigmoid 이전 정보를 얼마나 추가할지
실습
이거를 lstm 그리고 bidirectional 사용

3.gru
거의 같은데 구조를 조금 단순하게 바꿨다.
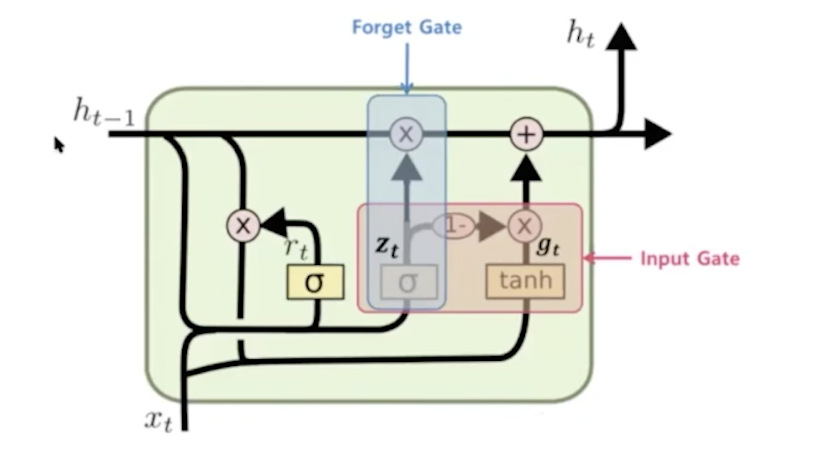
결론적으로 위와 같은 방법을 통해서 또 성능 개선이 가능하다.

데이터 -> 어떤 모델cnn, rnn ....이 적합한지 해보고 -> 파라메터 찾고, ...
4. elmo
rnn으로 단어를 예측하는 것은 문맥을 고려한 단어 예측

bidirection, stacking의 속성을 포함하고 있다.
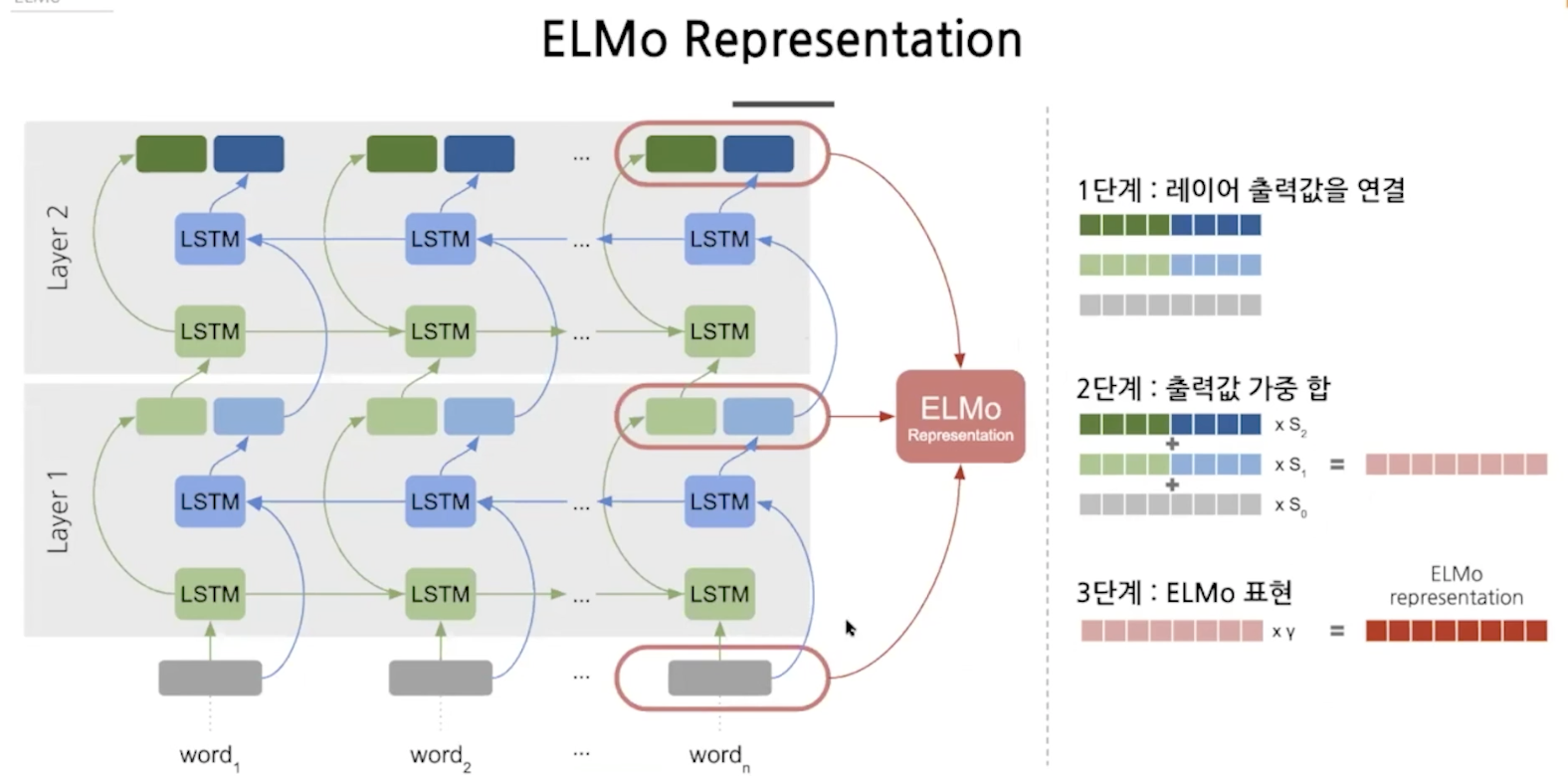
이렇게 하면 입력과 가까운 곳과 출력과 가까운 곳의 정볼르 활용해서 문법, 의미적 정보를 모두 활용할 수 있다.
이것도 결국 임베딩을 하는 방법이다.
13강 Elmo (embeddings from language model)
2)bidirectional
양쪽으로 정보를 줘서 예측하도록 한다. 학습속도가 더 빨라진다. 왜?
sota
translation
language modeling
text summarization
named entity recognition
question and answering

- word2vec, fasttext, glove : gift는 유일한 벡터로 표현
- elmo: 문맥에 따라 임베딩 -> 여러가지 벡터로 표현한다는 건가?
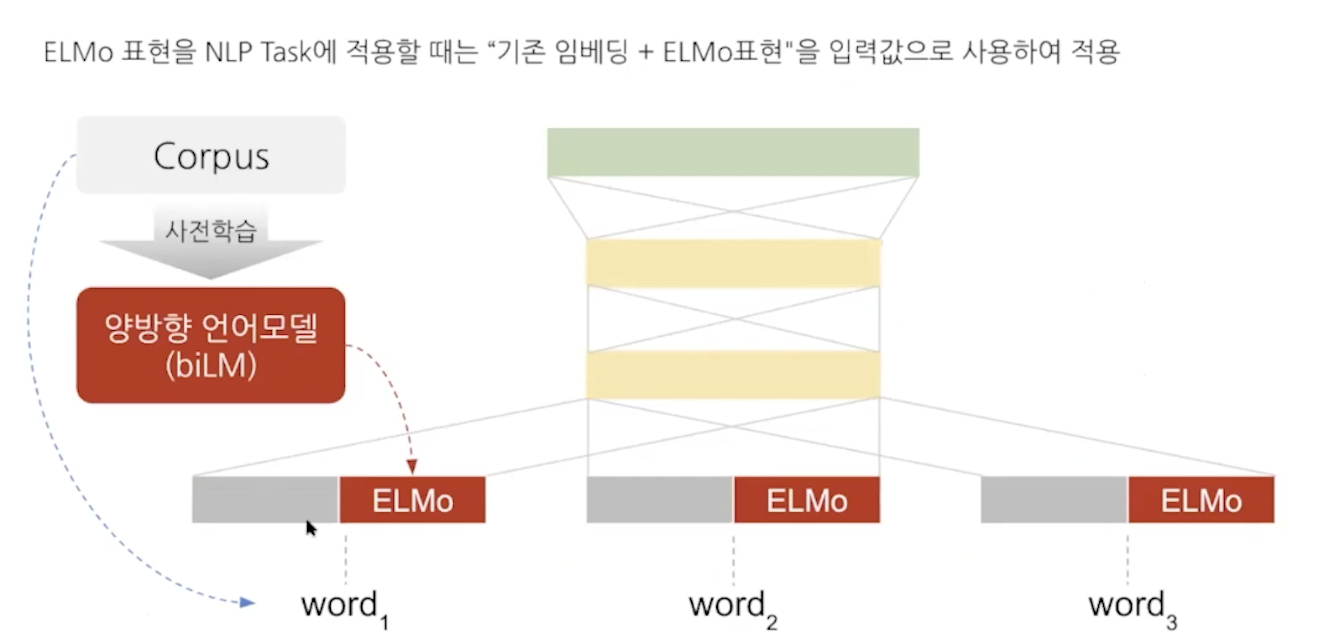
사전학습된 모델을 통해서 task를 해결하는데 이때 elmo representation을 사용한다.
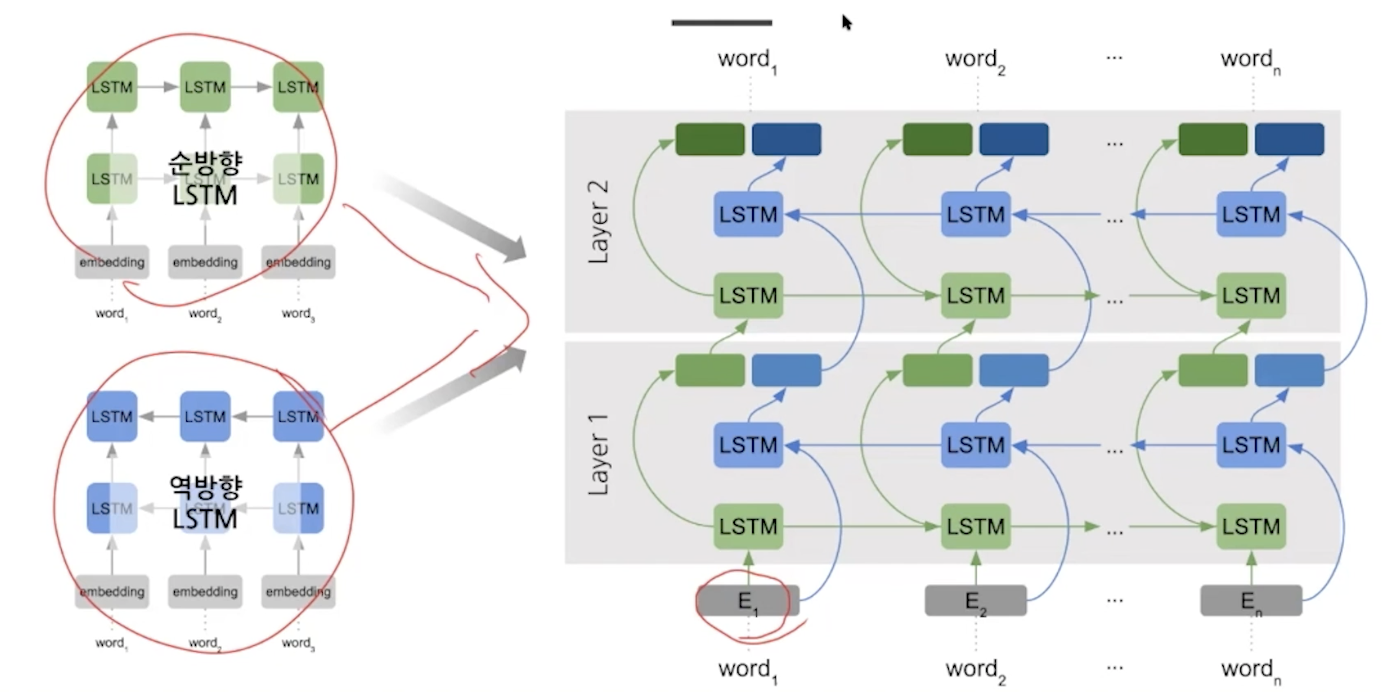
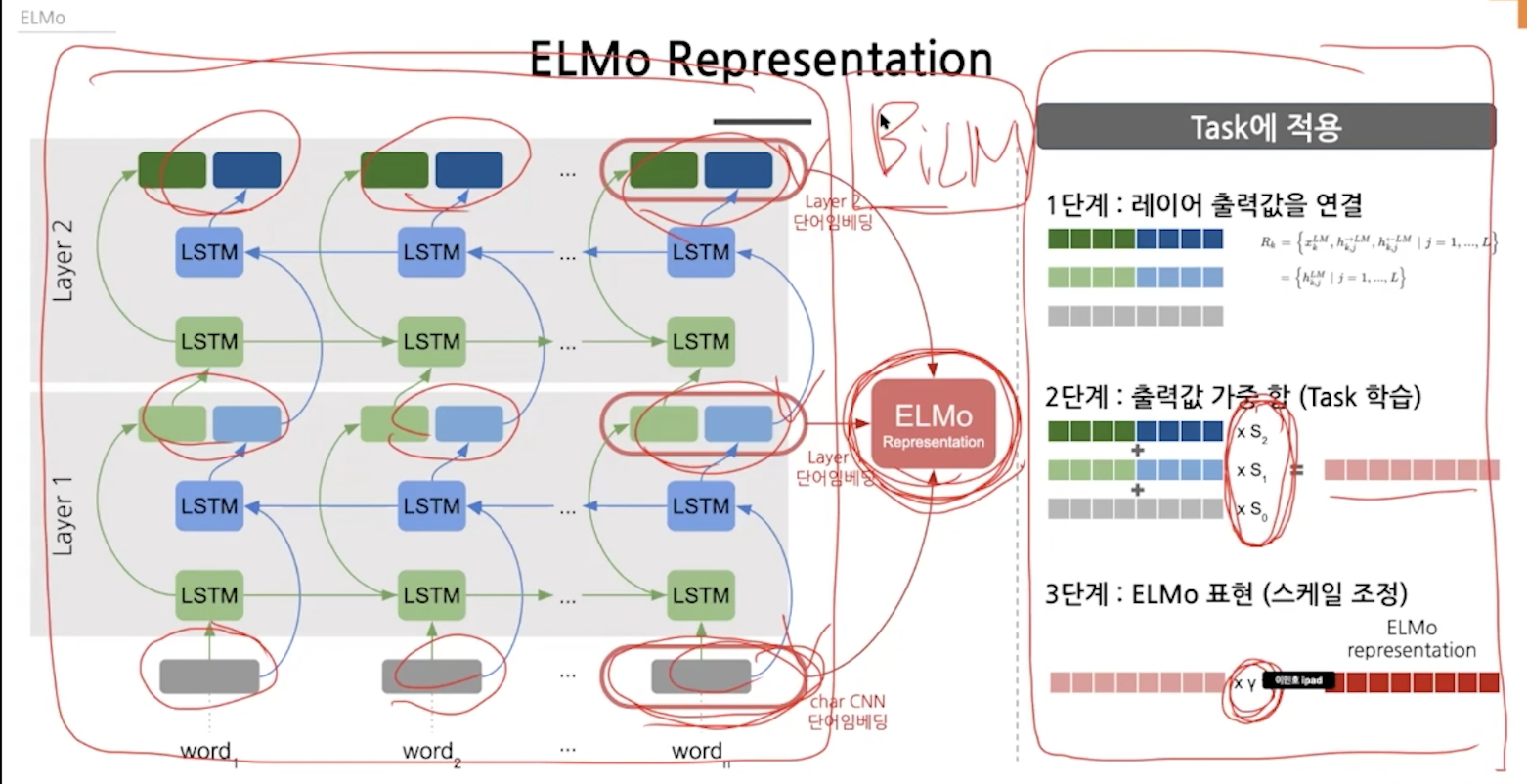
실제 bidirection은 순,역방향이 함께 진행돼서 레이어 하나가 끝나면 하나의 벡터로 만들어지는데 elmo는 두 개가 독립적으로 진행돼서 두개의 벡터(concat)가 만들어진다.
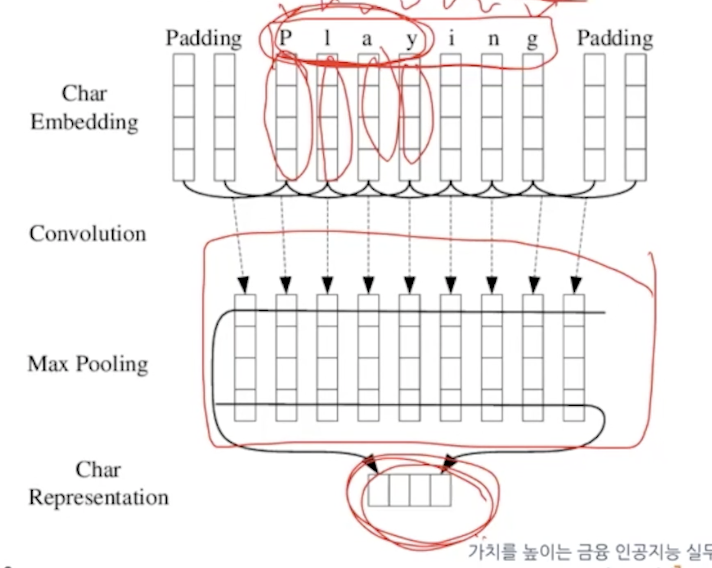
단어 벡터를 One hot vector, word2vec -> char cnn 임베딩 기법을 사용한다. cnn으로 단어를 임베딩한다.
fasttext처럼 playing만 학습해도 play를 추측할 수 있다.
stacking을 하면 레이어 위치마다 다른 정보를 담게돼서 각 레이어의 출력을 더하는 것이다.
가중합으로 합치는데 가중치는 학습하는 가중치다. task에 적용할때 적용하게 된다.
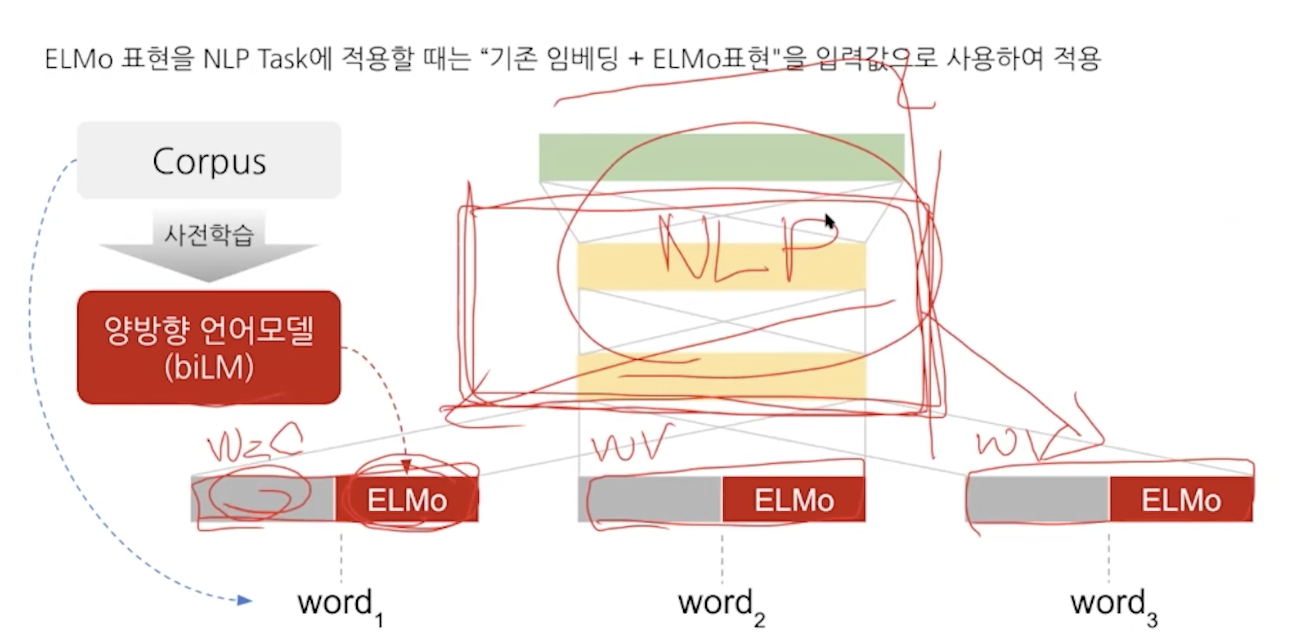
임베딩을 제외하고 task를 위한 layers만 학습하는 것이 아니고 elmo의 가중치 s를 학습하게 된다. 그래서 task에 적용될때 학습된다.
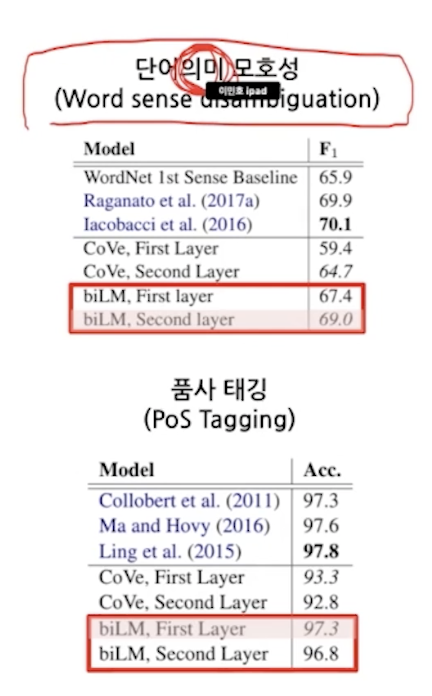
증명.
14강 seq2seq
참고:
'이제는 사용하지 않는 공부방 > Artificial intelligence' 카테고리의 다른 글
| how to decide number of layers and number of neurons (0) | 2021.09.20 |
|---|---|
| 자꾸 헷갈리는 axis 정리 (0) | 2021.09.14 |
| learn about a specific topic (0) | 2021.08.31 |
| senet: squeeze and excitation network (0) | 2021.08.12 |
| Attention mechanism (0) | 2021.08.10 |