1. 정의
사용자가 구매한 상품 중에서 유사한 상품을 추천해주는 시스템
2.방법
아이템을 벡터로 표현하고 유사한 벡터(다른 아이템)을 찾으므로써 추천을 해준다.
ex. text를 word2vec을 이용하든가, image를 이용해서 벡터로 바꿔주고 추천을 해준다.
1) 벡터의 유사도를 찾는 방법: 문서간의 유사도를 계산한다.
- 코사인 유사도
둘의 방향을 구분하는 세타를 중심으로 본다.
세타가 0으로 같으면 유사도가 1, 세타가 90도면 유사도가 0, 세타가 180이면 -1로 가장 최소의 값
문서1 0 0 0 1 0 1 1 0 0
문서2 0 0 0 1 1 0 1 0 0
문서1과 문서2의 경우 내적 값은 1 + 1이고, 크기는 루트3이므로 2/3 = 0.66..이된다.
벡터의 크기가 중요한 경우에는 좋지않다.
- 유클리디안 유사도
공식: 유클리디안 유사도 = 1/(유클리디안 거리 + 1e-05)
*1e-05는 분모가 0이되는 것을 방지
*유클리디안 거리 = |p - q|
- 코사인과 유클리디안의 차이점
코사인은 두 벡터 사이의 각도를 중심으로 본다.
유클리디안은 두 벡터의 거리를 중심으로 본다.
- 피어슨 유사도
상관관계를 분석할때 사용한다.
- 자카드 유사도
집합에서 얼마나 결합된 부분이 있는지를 말해준다.
공식: 교집합/합집합
- 그 외에도 다양한 유사도 함수가 있다.

다이스, 디벌젼스...등등
실제로는 어떤 도메인이냐에 따라서 유사도 함수를 결정한다.
2)아이템 -> 벡터 변환 방법
아이템은 text type, image type, tabular type이 있지만, 텍스트 형태로 가정하고 알아보자.
- TF-IDF
특정 문서에서 특정 단어가 얼마나 등장 -> 단어 빈도 tf -> TF(d,t) 문서 d마다 특정 단어 t의 등장 횟수
전체 문서에서 특정 단어 얼마나 등장 -> 역문서 빈도 df -> DF(t) t가 등장한 문서의 수
다른 문서에서는 등장 안하지만 특정 문서에서만 자주 등장 -> 단어의 가중치 계산 -> IDF(d,t) df에 반비례
공식: tf * idf = tf-idf
예시: https://chan-lab.tistory.com/24
[Python/Jupyter] 본격 TF-IDF 개념 해부
안녕하세요! 은공지능 공작소 운영자 파이찬입니다. 오늘은 TF-IDF 벡터화에 대한 내용을 다루겠습니다. 자연어처리를 하다 보면 많이 등장하는 Feature extraction 기법입니다. 1. TF-IDF의 개념 TF-IDF의
chan-lab.tistory.com
counter vectorizer 방법을 사용하면 조사, 관사 the, this ...처럼 의미 없지만 문장에 많이 나오는 단어들을 높게 해주는 단점이 있다. 이에 패널티를 줘서 중요한 단어만을 잡아내는 것이 TF-IDF 방법이다.
실제로 계산을 한다고 하면 문서들이 있고 각 문서의 내용을 본다. 각 내용은 단어들로 이루어지므로 문서마다 TF를 구해줄 수 있다.
그리고 전체 문서에 대해서 DF를 구할 수 있다. 그러면 공식을 통해서 IDF를 구해준다.
(*IDF로 바꿀 때 DF(특정 단어가 등장한 문서의 수)에 역수를 취해주면 비정상적으로 많은 관사나 조사같은 것들에 페털티를 부여할 수 있다.)
마지막으로, TF와 IDF를 곱해주면 최종 matrix가 완성돼서 문서마다 벡터가 생긴다.
이제 이 matrix의 문서마다 벡터를 보고 서로 코사인 유사도를 이용하면 어떤 아이템끼리 유사한지 알 수 있다.
정리하자면, 아이템을 벡터로 바꿔서 유사도를 구하고자 하는데 이때, TF-IDF라는 방법을 사용해서 벡터로 바꿔주고 코사인 유사도를 사용해서 유사도를 구한 것이다.
장점, 직관적인 해석 가능
단점, 큰 메모리를 차지한다. -> sparse한 데이터임.
3.실제 코드로 이용해보기
1) 기본 편


위의 설명한 과정과 동일한데 문서를 단순하게 조작하여 숫자, 특수문자 등은 배제한 것을 알 수 있다.
실제로는 숫자나 특수문자 등을 전처리해주는 과정을 거쳐야 한다.
2) 심화 편
www.kaggle.com/chocozzz/00-tf-idf-2
00. 컨텐츠 기반 추천시스템 - TF-IDF를 이용한 추천시스템#2
Explore and run machine learning code with Kaggle Notebooks | Using data from T Academy Recommendation2
www.kaggle.com
data를 받아서 dataframe으로 바꿔주고 overview column을 중심으로 유사도를 측정하기로 했다.
데이터가 많으니깐 코랩이 터져서 10000개 데이터만으로 이용려고 loc함수를 이용했다.
overview에서 null값을 삭제해주고, tfidifvectorizer을 통해서 fit_transform으로 함수를 적용하여 문서를 벡터화 시켜주었다.
tfidf matrix를 구했고 cosine similarity를 이용해서 cosine matrix를 구했다.
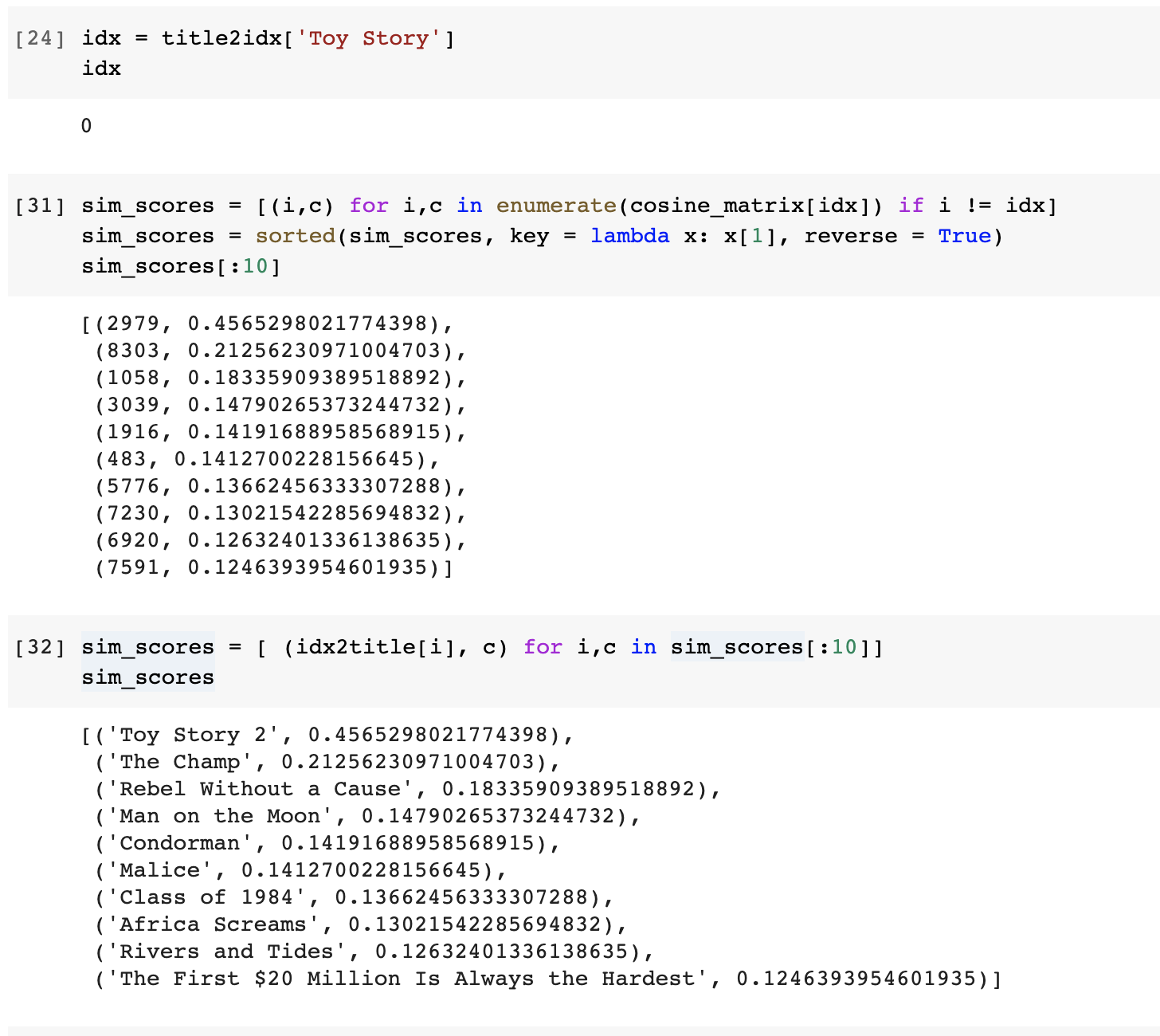
특정 영화이름과 matrix의 index를 맞추기 위해서 idx2title, title2idx를 구했고, title을 idx로 바꿔서 idx에 해당하는 cosine matirx의 행을 보고 해당 행의 내용은 나머지 전체 문서와의 유사도 이므로 그것을 가져오는데 (index, 유사도)로 가져오게 된다. 이때, index를 title로 바꾸기 위해서 idx2title함수를 사용하였다
sim_scores = [ (idx2title[i], c) for i,c in sim_scores[:10] ]




*이 글은 토크on세미나 유튜브를 통해 공부한 내용입니다.
'이제는 사용하지 않는 공부방 > Artificial intelligence' 카테고리의 다른 글
| [밑바닥부터 시작하는 딥러닝] 4강 신경망 학습 핵심정리 (0) | 2021.04.25 |
|---|---|
| [밑바닥부터 시작하는 딥러닝] 3장 신경망 핵심정리 (0) | 2021.04.24 |
| [fast ai] chapter9_tabular modeling (0) | 2021.04.18 |
| [fast ai] production (deep learning course 2) (1) | 2021.01.18 |
| fastai vision tutorial/ Points (1) | 2021.01.16 |