저번에 tf-idf를 통해 메모리상의 문제가 생긴다는 것을 알았다.
그래서, 텍스트나 이미지 같은 아이템을 벡터로 표현할때 word2vec기법을 사용해보자.
모든 단어들을 사용하여 메모리상의 문제와 한번에 학습을 진행해야해서 배치단위로 나눌 수 없었다.
따라서, 의미기반으로 벡터를 만들어서 메모리를 줄여보자.
1. word2vec
주변 단어(맥락)으로 중심단어나 주변 단어를 추론하는 것이다. 이때, 주변 단어 맥락이 유사성을 만들어준다.
나는 강아지를 좋아한다.
나는 고양이를 좋아한다.
안구 건조증 환자는 눈물 약을 사용한다.
라식 환자는 눈물 약을 사용한다.
나는 ~ 좋아한다 사이에 있기때문에 강아지와 고양이는 유사한 단어라는 것을 알 수 있다.
같은 맥락으로 안구 건조증 환자와 라식 환자는 유사성이 있는 단어라는 것을 알 수 있다.
이러한 유사함을 통해서 저차원 벡터로 임베딩하는 기법이 word2vec이다.
정리하면, 아이템을 word2vec방법을 통해 벡터화하고 코사인 유사도를 이용해서 추천을 해줄 수 있다.
2.cbow
주변 단어를 통해서 중심 단어를 예측 한다.
*윈도우의 크기: 주변 단어를 윈도우의 크기만큼 보는 것이다.
hey what are you doing?에서 window가 1이면 are을 중심으로 what과 you이다.
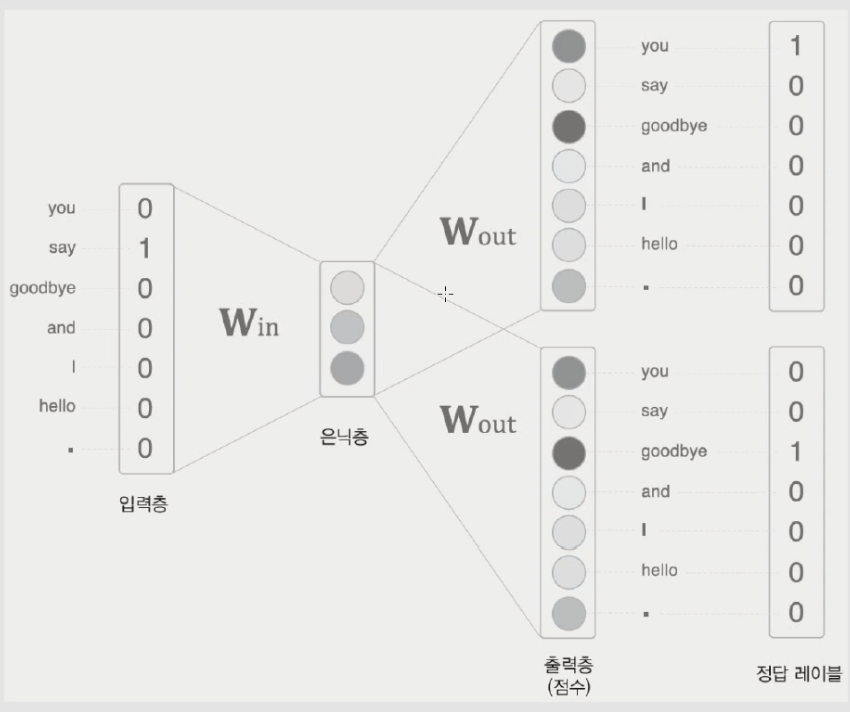
-알고리즘 구현 dnn

1) input: one hot vector
주변 단어1 -> 중심 단어 예측
주변 단어2 -> 중심 단어 예측
2) input과 w_in를 곱하는데 이때, w_in의 차원은 사용자가 정해준다.
(저차원으로 정해줄 수 있다.)
w는 단어의 임베딩 값이다.
(단어를 벡터화한 것이다.)
3) hidden state의 값을 w_out과 곱해서 score을 구하고 softmax를 취해서 각 단어가 나올 확률을 계산한다.
4) 정답 label과 prediction의 loss를 cross entorpy를 통해서 구해준다.
5) loss를 가지고 backpropagation을 통해서 weight를 업데이트

ds = prediction - label
앞의 ds와 h(hidden layer)를 np.outer한다.
da도 마찬가지 과정을 통해서 구한다.
w_in에 대해서도 구해준다.
그러면 w_in_new = w_in - learning_Rate * dw_in을 통해 params를 업데이트 해줄 수 있다.
6) 이렇게 w_in을 개선하다보면 단어들을 임베딩한 벡터가 된다.
*np.outer에 대해서 알아보자.
numpy.org/doc/stable/reference/generated/numpy.outer.html
7) 다른 문맥에 대해서도 cbow algorithm수행을 해준다.

3.skip-gram
중심 단어를 통해서 주변 단어를 예측한다.
cbow보다 성능이 좋다. 왜냐하면, task가 더 cbow보다 어렵기 때문이다. 그래서 더 똑똑하게 학습을 진행한다.
cbow와 같지만 인풋과 아웃풋의 형태가 달라진다.
중심 단어 -> 주변 단어1, 주변 단어2 예측
4. 코드는 gensim패키지를 이용한다.




5. 컨텐츠 기반 모델
-장점
cbf는 item feature을 이용하기 때문에 추천된 이유를 설명하기 용이하다.
처음 사용자나 처음 등록된 아이템에 대해서 cold start problem을 해결할 수 있다.
(들어올 때, 바로 임베딩하고 유사도 할 수 있다.)
-단점
feature을 제대로 추출하지 못하면 정확도가 많이 낮아서 도메인 지식이 중요하다.
(게다가 메타데이터도 중요하다.)
그래서 cf와 cbf를 같이 적절하게 활용하는 경우가 많다.
*이 글은 토크on세미나 유튜브를 통해 공부한 내용입니다.
'이제는 사용하지 않는 공부방 > Artificial intelligence' 카테고리의 다른 글
| [추천시스템] 협업 필터링 (KNN, SGD, ALS..) (0) | 2021.04.30 |
|---|---|
| [밑바닥부터 시작하는 딥러닝] 5강 오차역전파법 핵심정리 (0) | 2021.04.30 |
| [밑바닥부터 시작하는 딥러닝] 4강 신경망 학습 핵심정리 (0) | 2021.04.25 |
| [밑바닥부터 시작하는 딥러닝] 3장 신경망 핵심정리 (0) | 2021.04.24 |
| [추천시스템] 컨텐츠 기반 추천시스템 TF-IDF (0) | 2021.04.19 |