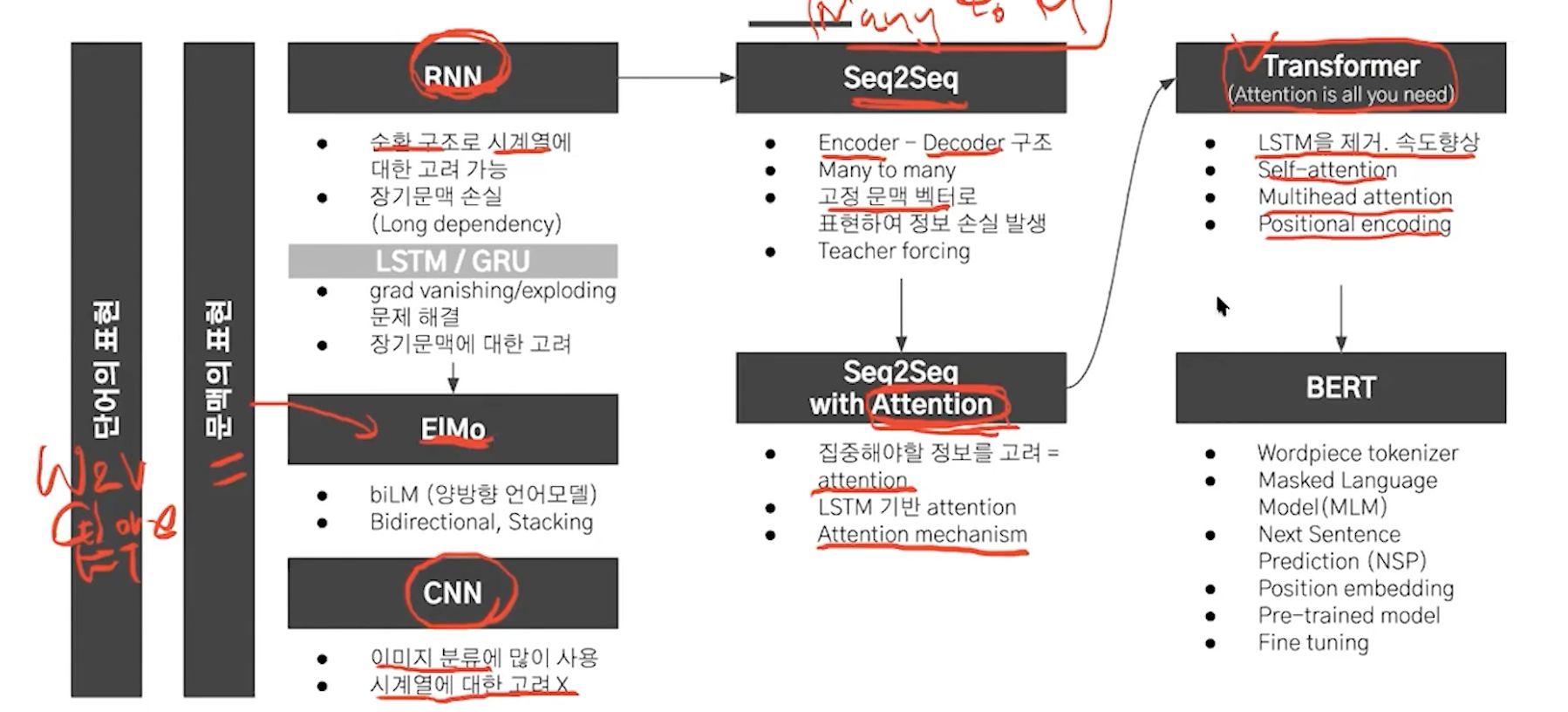
seq2seq에 attention을 사용하니깐 성능이 개선됐는데 아직 rnn을 사용해서 속도가 느리다.
이를 해결하기 위해서 attention만 사용해보자.
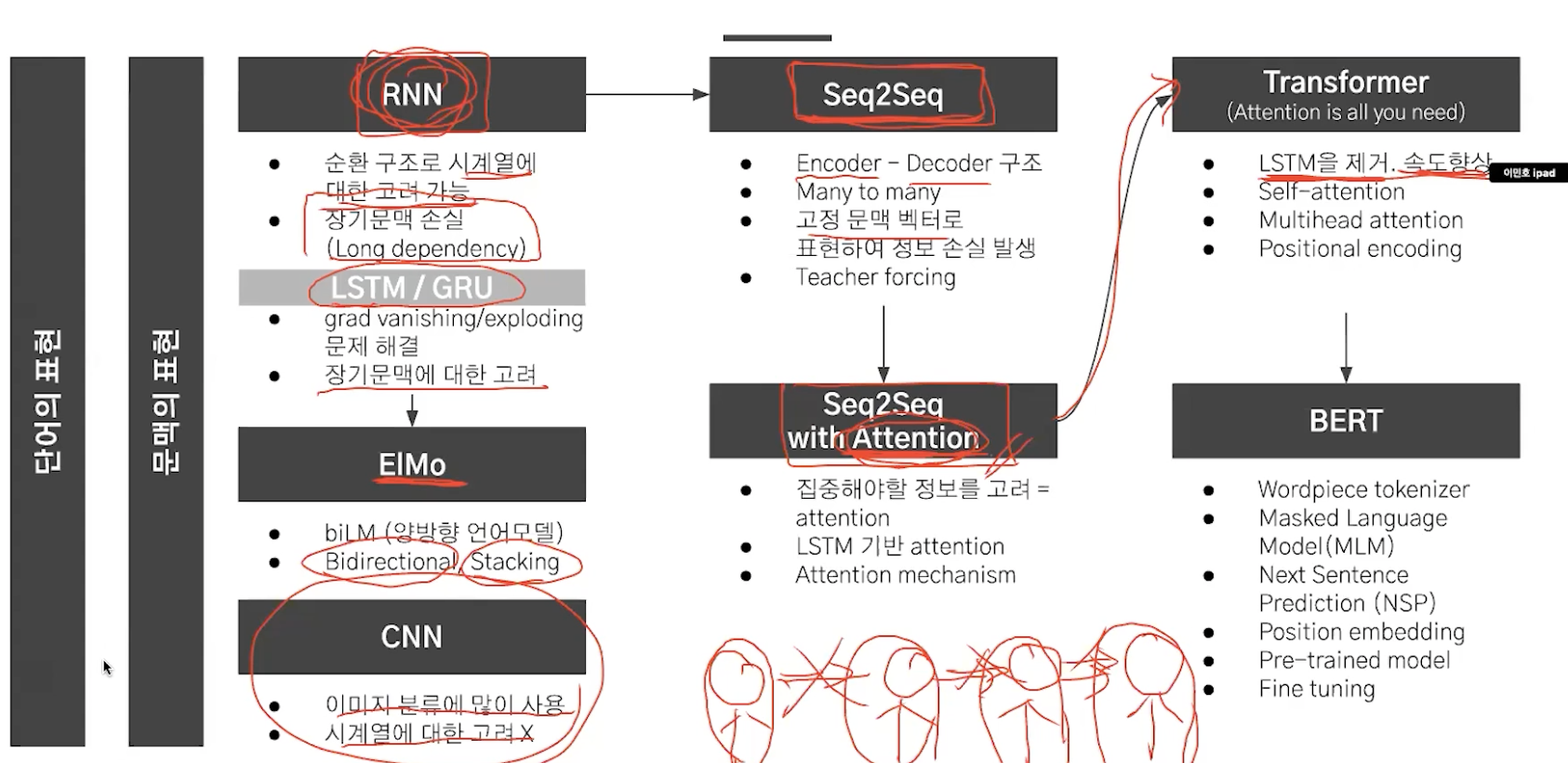
cnn, rnn을 사용하지 않는다!
long term dependency problem 해결
parallelization 사용

한번에 쭉 연산을 한다.
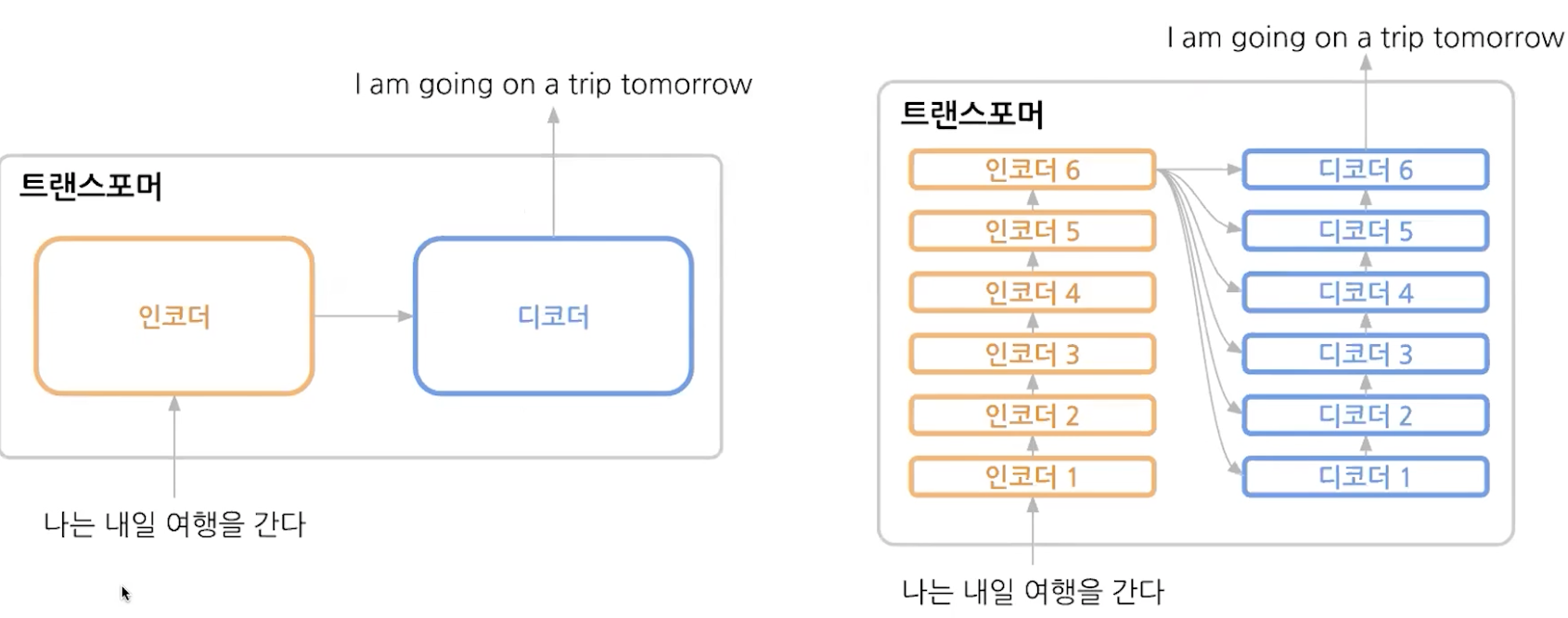
여러개의 인코더와 디코더로 이루어져있다.
레이어를 여러개하면 더 빠르게 수렴한다.
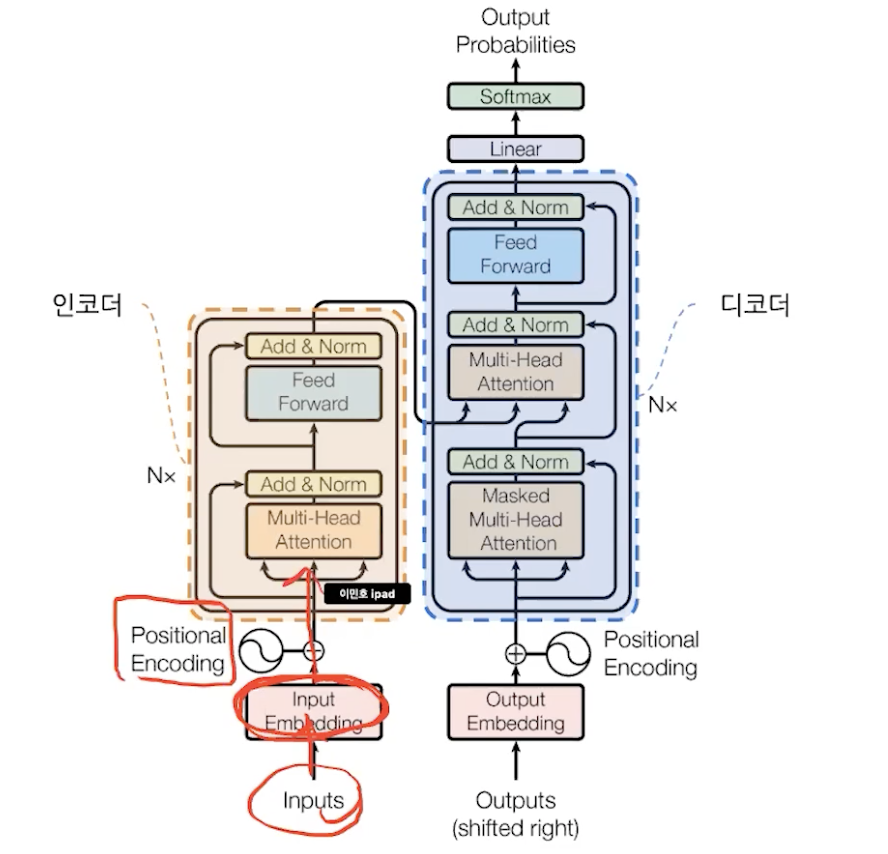
positional encoding -> attention -> feed foward
attention만으로 encoder, decoder 구성
1. positional encoding
단어 임베딩에 positional vector을 더해서 순서에 대한 고려를 해준다.
와 똑똑하다..
2. encoder & decoder
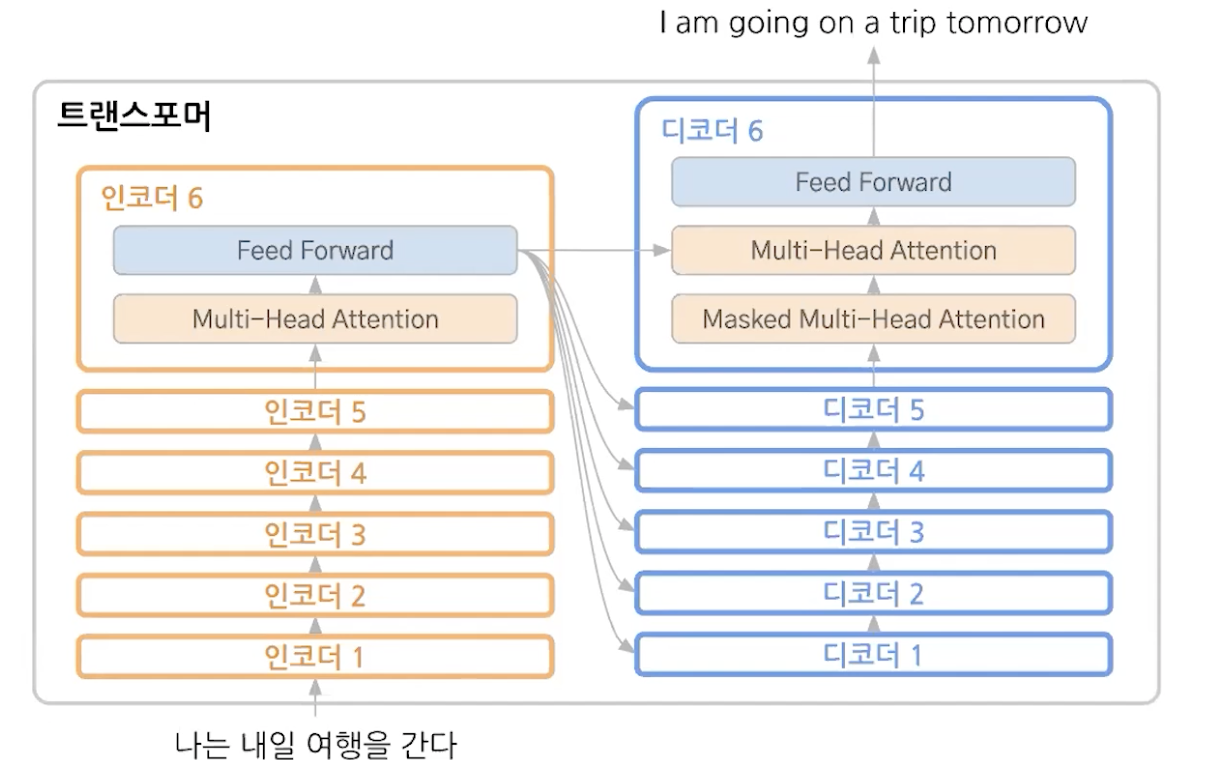
attention -> attention vector -> feed forward ( fc )
3. self attention
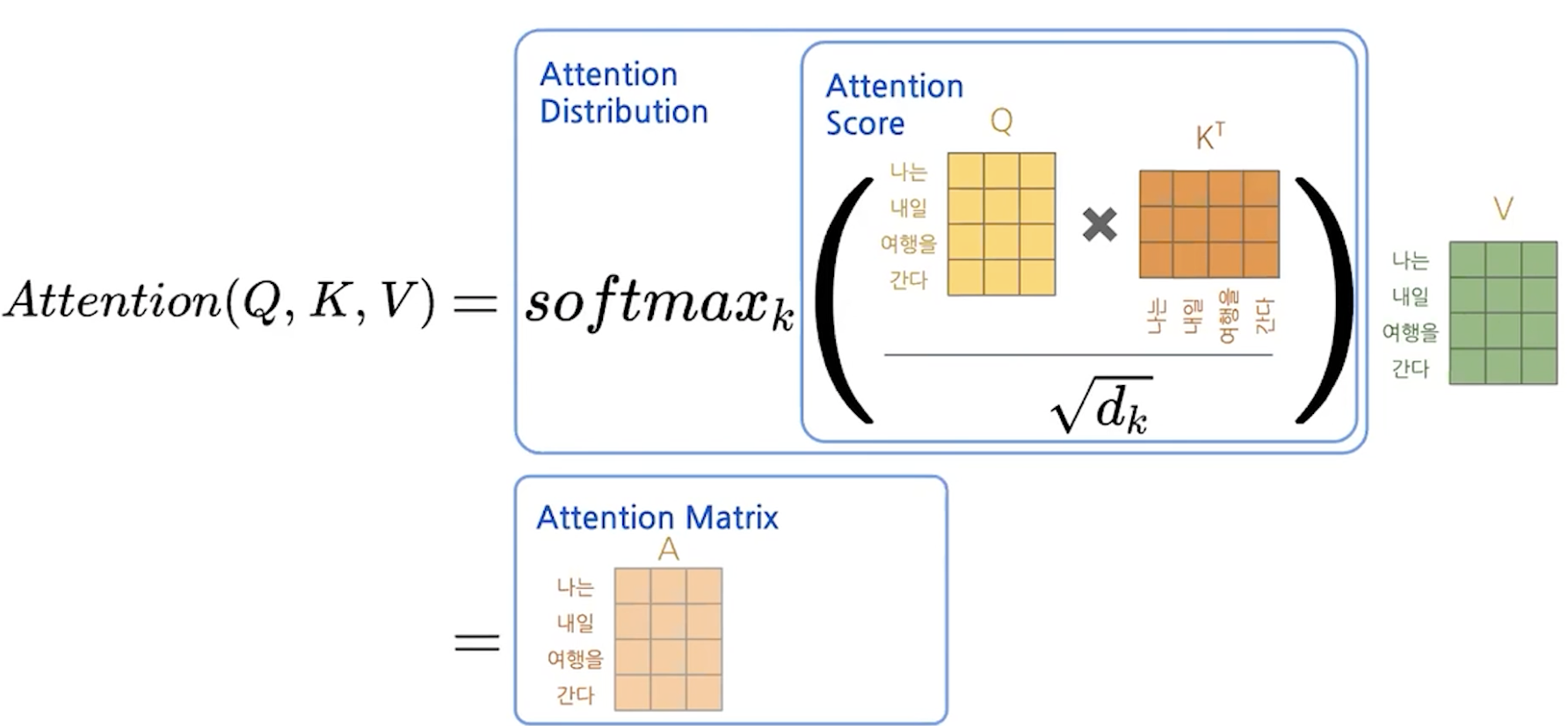
scaled dot-product attention
4. masked multi head attention

디코더끼리 attention vector을 만들고 인코더에서 context vector을 받아서 attention vector을 또 만든다.
학습 시, teacher forcing
예측 시, 그냥 사용
여기까지 정리해보면
rnn, cnn x -> attention o
encoder,decoder은 attention만으로 이루어져있고 순서정보는 Positional encoding을 사용한다.
1. encoder
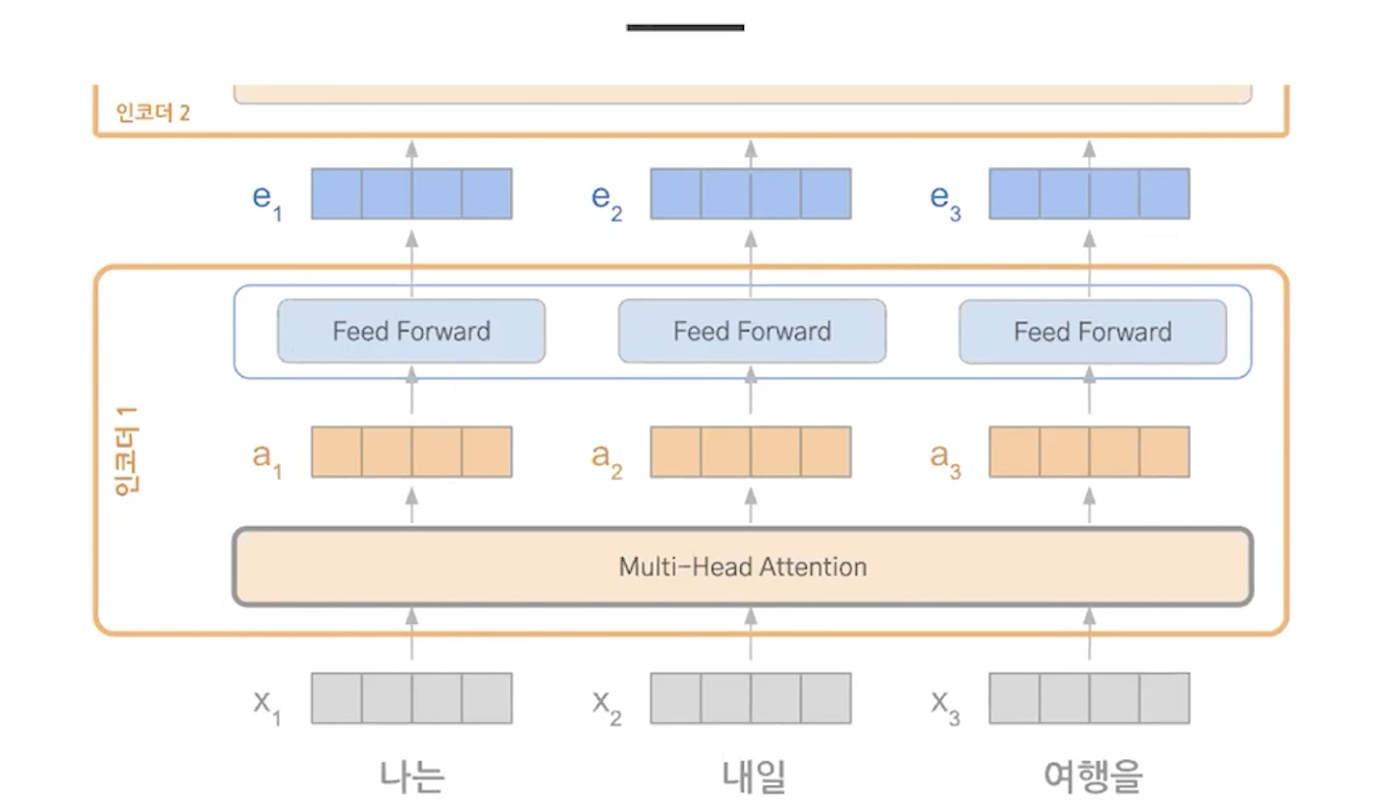
1) multi head attention & feed forward
encoding에서도 attention을 한다. attention vector를 feed forward를 통해서 학습을 한다.
attention을 계산하고 학습하고 ... 를 반복
Q. 입력된 문장밖에 없는 데 어떻게 attention을 하냐?
A. self attention을 한다.
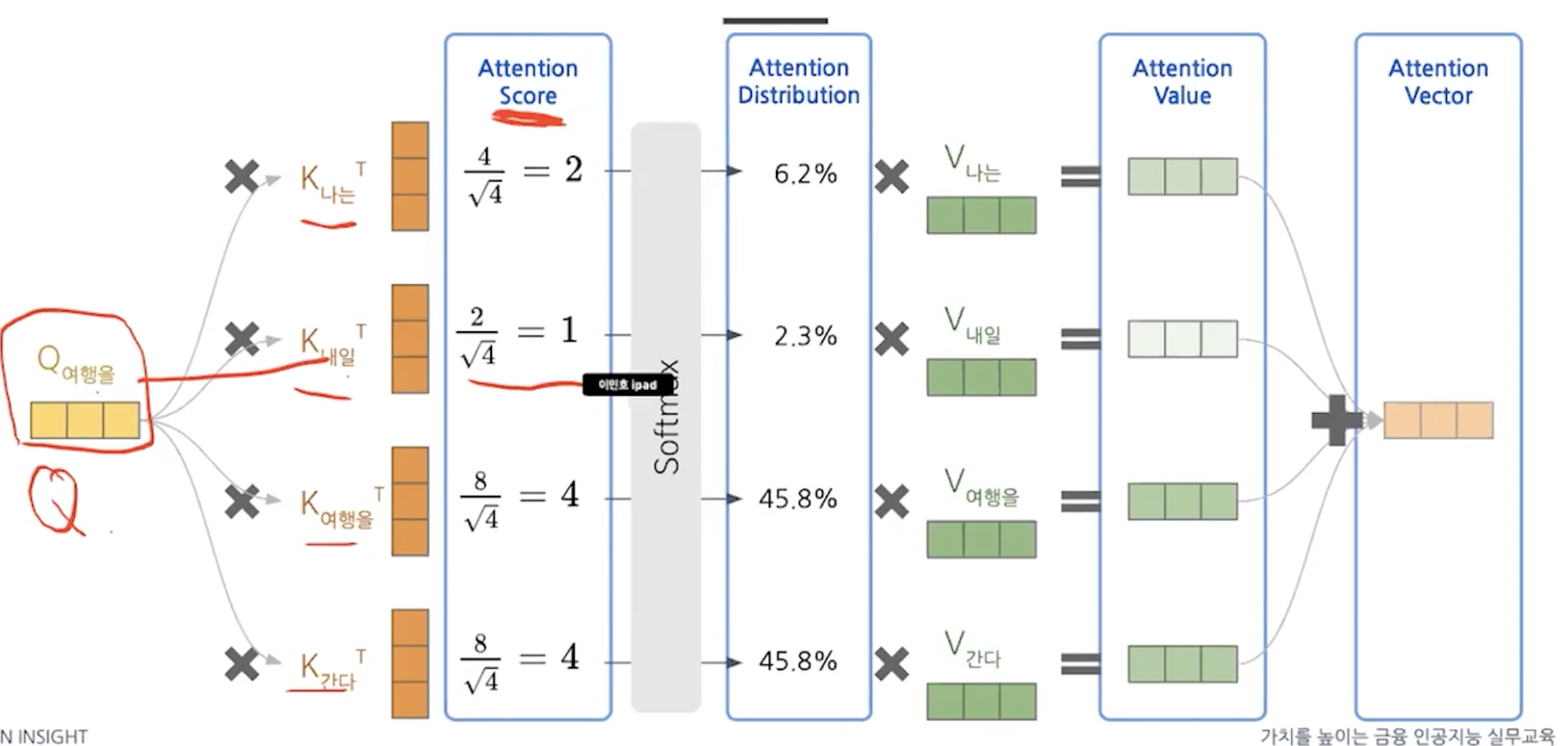
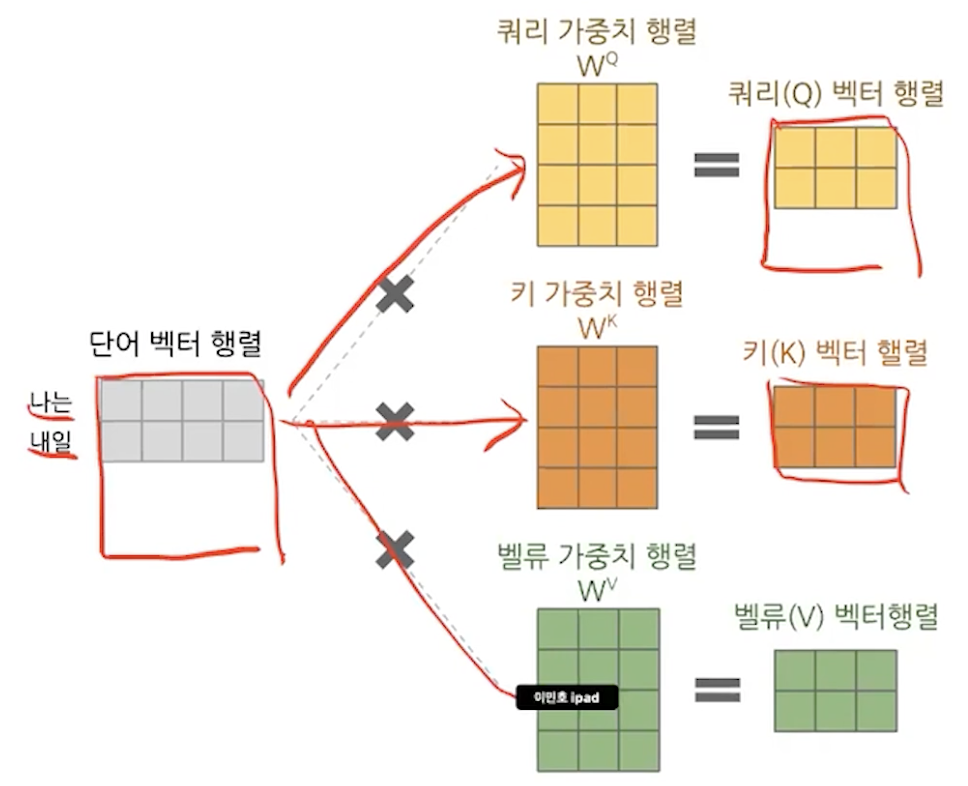
단어 -> 임베딩 -> 어텐션 스코어 계산 -> fc -> encoder의 output
- multi head attention (self attention == scaled dot - product attention)
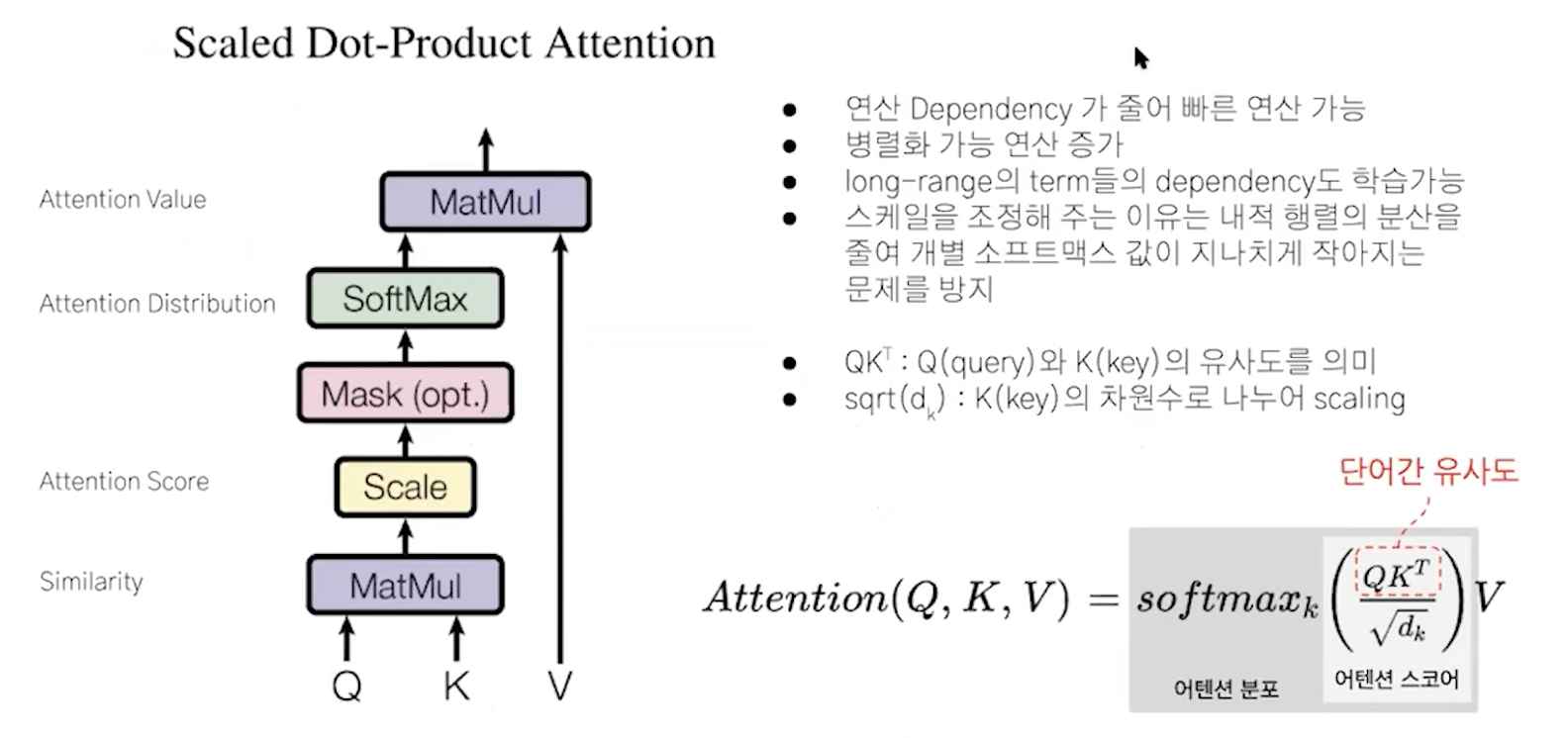
Q: 뭘르 기준으로 attention 계산
K: query의 비교 대상
V: attention score -> 분포 -> 이 value를 사용한다.
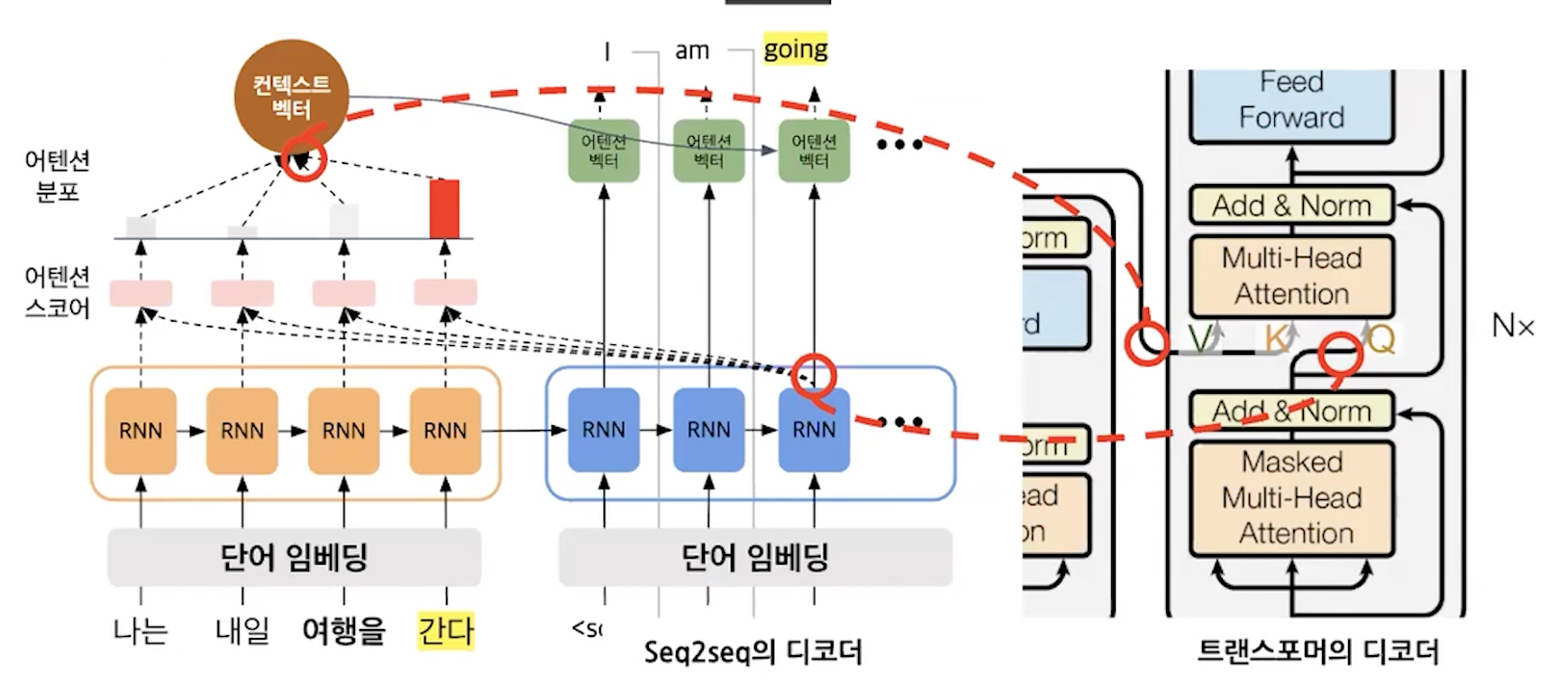
Q, K, V를 주의깊게 보자.
k는 encoder_outputs를 의미한다.
이해했으면 앞선 그림을 다시 살펴보자. 그러면 Q,K를 dot product하는 것은 결국 seq2seq with attention에서 decoder output과 ㅑencoder outputs간의 attention score을 구하는 것과 같다고 볼 수 있다.

질문: '나는'이 주어라서 '여행을'과 attention이 높을 가능성이 있다고 했는데 단어의 유사도 자체는 높지 않은 것 아닌가? 그러면 처음에 임베딩했을때 '나는'에 대한 벡터와 '여행을'에 대한 벡터가 가까이 있어야겠네? word2vec과 같은 방법으로 하면 되나?

대박... 이렇게 하면 문맥을 이해하는 효과가 확실히 있겠다.
그리고 attention distribution을 v와 곱하게 되면 앞선 예시와 비유해볼때 context vector with attention을 구했다고 볼 수 있다.
앞에 것이 계산되고 순서대로 계산했었는데 여기서는 matrix multiplication으로 병렬화가 가능하여 연산을 빠르게 처리할 수 있다.
질문:scale부분 설명? 1시간 4초
위 과정을 여러번 거친 것을 multi head attention
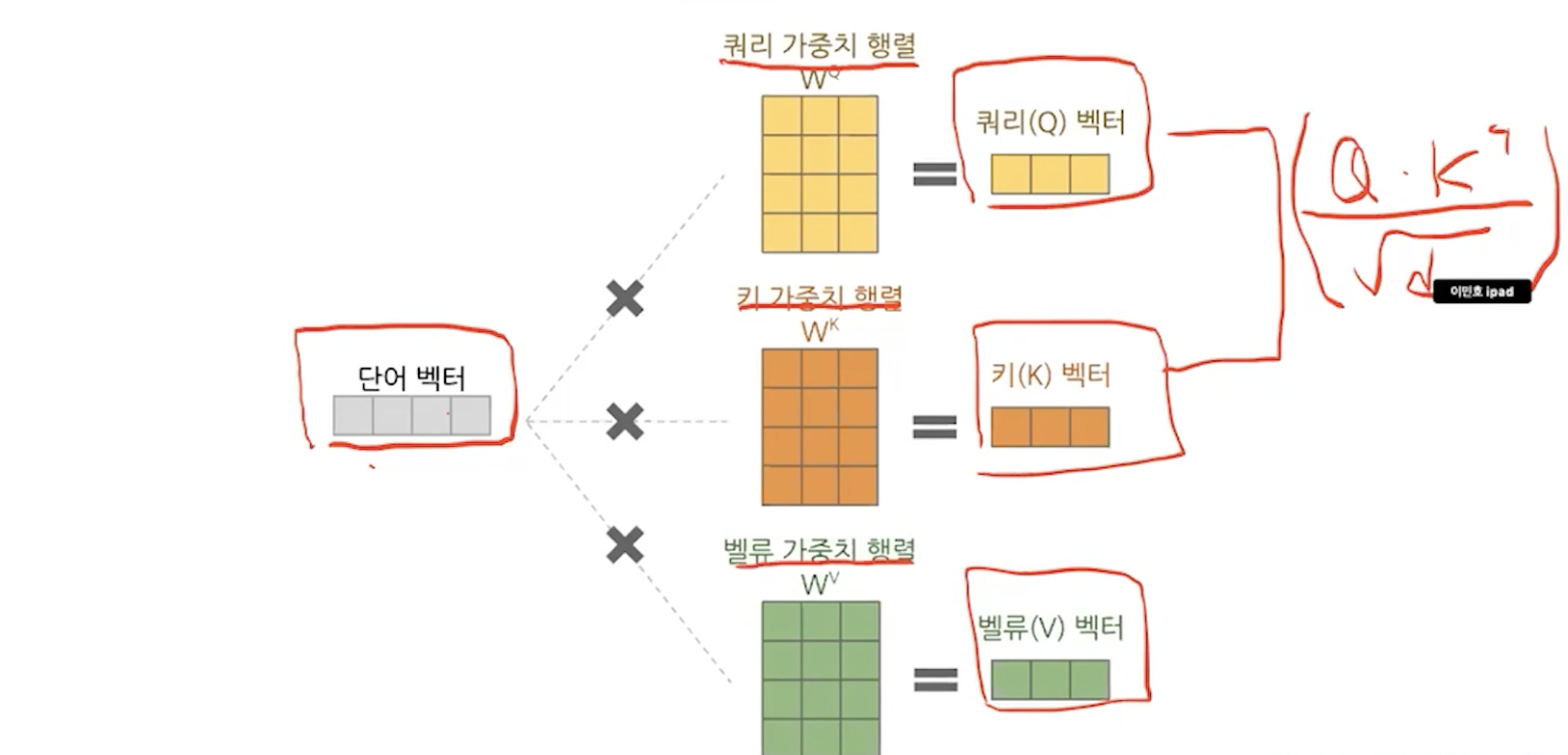
사실은 단어벡터가 여러개로 이루어져있고 그것을 아래와 같이 행렬로 처리할 수 있다. 따라서 시간에 많은 개선을 이루었다.
self attention 정리
2) multi head attention

가중치를 여러 개로 두고 앞선 과정을 여러번 반복한다.

cnn에서 필터를 여러개 적용하는 것처럼 생각하면 된다.
Q. 각 head별로 weight가 어떻게 초기화되냐가 차이인건가?
1시간 13분
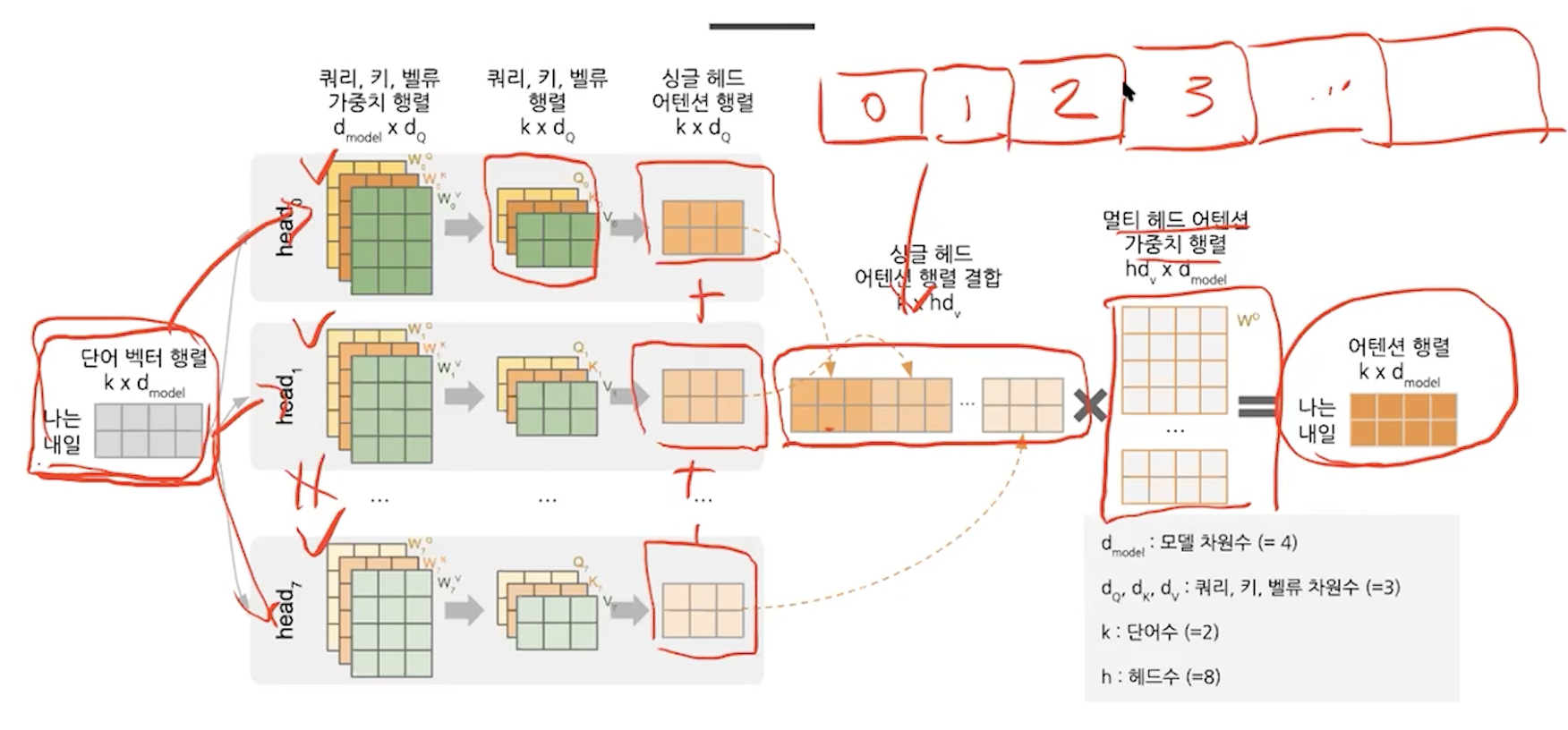
multi head -> concat -> linear ( 싱글 헤드 어텐션 행렬은 scaled dot product를 거친 상태를 의미힌다.)
지금까지 multi head attention을 봤고, 이제 fc를 보자.

이 과정은 왜 거치지? 학습을 하기 위해서 ㅇㅇ 이해가 잘 안돼.
attention -> fead forward로 학습 이 과정을 6번 거친다.
2. decoder
차이점.
masked multi head attention이 추가되었다.
그리고
multi head attention에 인코더6의 내용이 들어온다.

masked

'나는'을 학습하면 '다음에 뭐가 나올지 모르는 상태'이다. 이를 반영한다. 그래서 다음 단어들을 masking한다.
토큰이 지날수록 보는 단어가 더 많아진다.
encoder & decoder 차이

이 이유는 미리 답이 준비되어있는 입력과 다르게 예측에서는 해당 단어 뒤의 단어를 모르기때문이다.
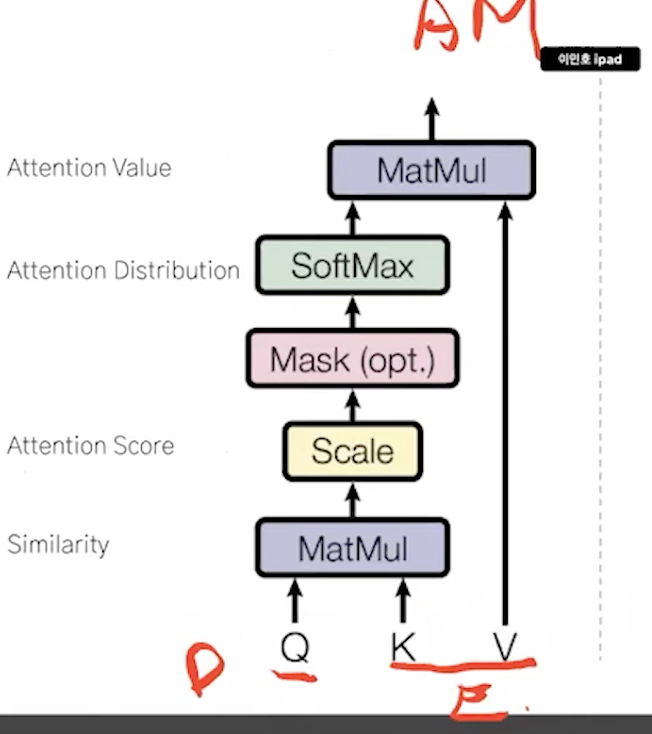
디코더에서는 Q가 decoder, K,V가 encoder의 것이다.
총정리.
디코더에서 학습할때 디코더의 입력은 다음 단어가 뭐가 나올지 모른다는 가정하에 학습을 해서 masking을 하고 self attention을 하고
masked multi head attention의 결과를 기준인 Query로 두고 인코더의 결과를 K, V로 둬서 attention vector을 구해준다.
이때, V 같은 경우는 encoder의 hidden state값을 모아둔 것이라고 이해할 수 있는데 그렇다면 k는 뭘까? k와 v는 인코더의 출력으로 같다.
최종

*label smoothing
labeling mistake를 해결해주는 방법
ex. 0010으로 특정 단어 선택
1 -> 0.9
0 -> 1
why? 구체적인 이유는 없지만 암튼 그럼 drop out이랑 비슷한 느낌 좀 더 일반화할 수 있다.

3. input embedding
word2vec, one-hot-encoding ...etc + positional encoding
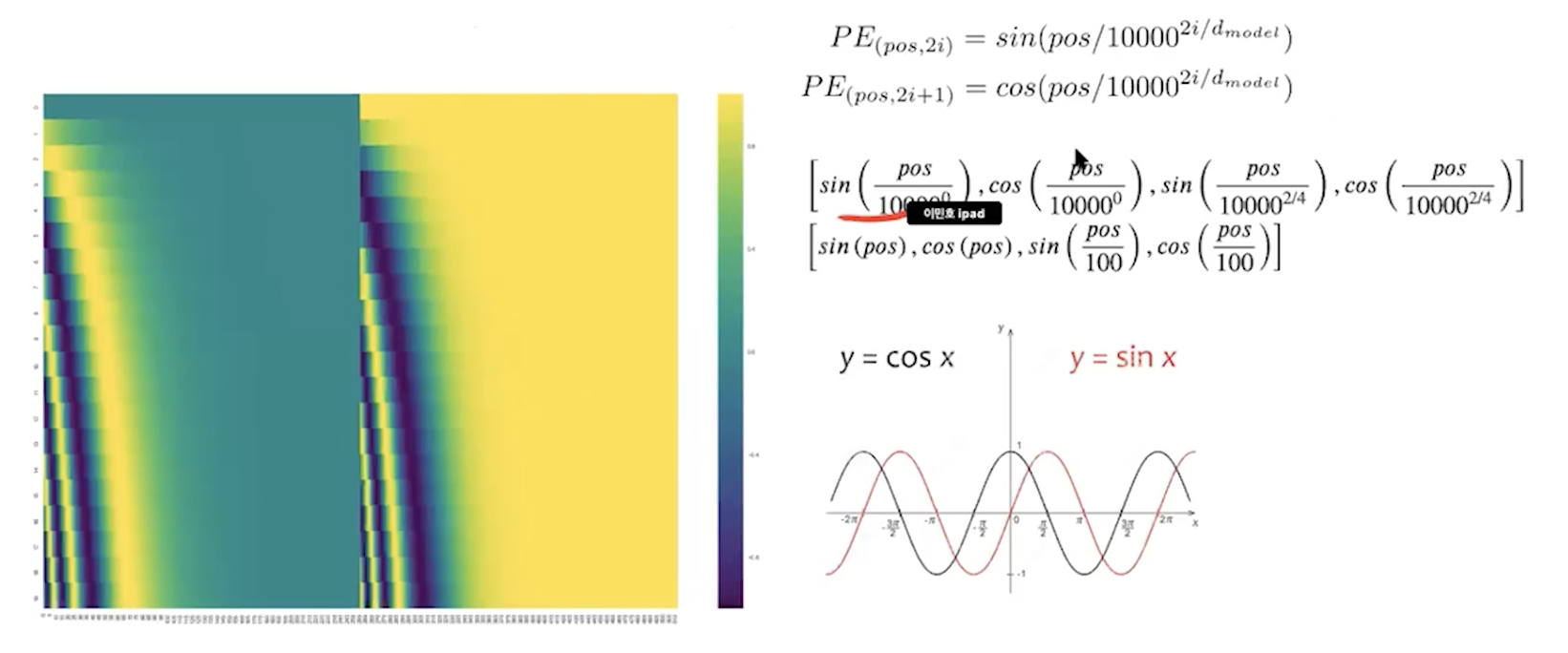
*positional encoding
깊게 이해하려고 하지말기, 유니크한 벡터를 만들기 위해서 cos, sin을 이용한다.
4. 잔차연결 & 정규화
add & norm == residual connection & normalization
원래 입력된 값이 사라지니깐 이를 다시 복원해주는 과정이 residual connection

더하고 정규화하는 이유는?
5. 학습
단어 -> id -> 임베딩 -> positional encoding -> encoder [ multi head attention -> residual connection -> train ] -> decoder [ masked multi head attention -> residual connection -> multi head attention with encoder outputs -> train] -> linear -> softmax
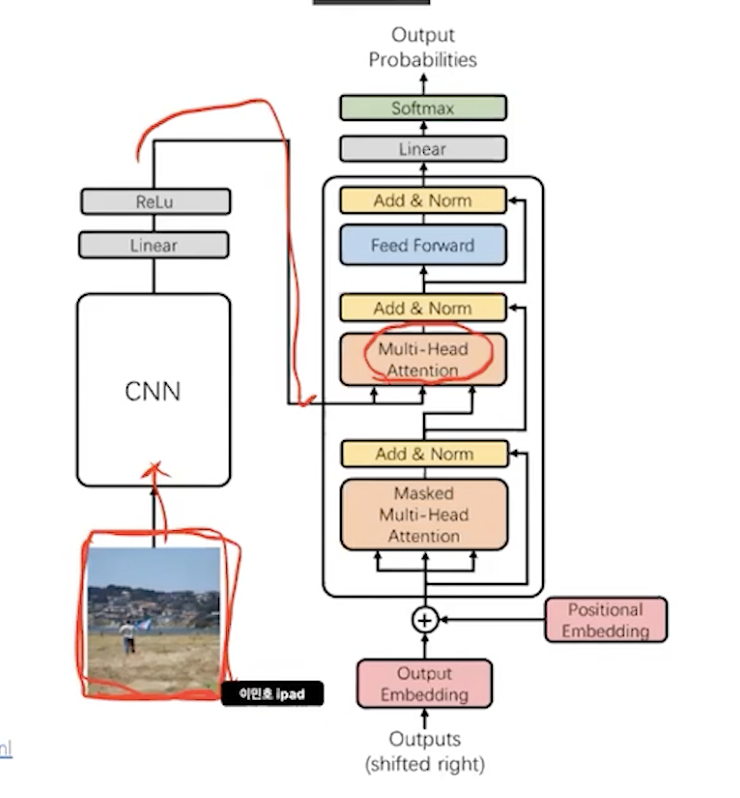
6. 활용
decoder만 사용할 수 있다.
bert vs open ai gpt vs elmo
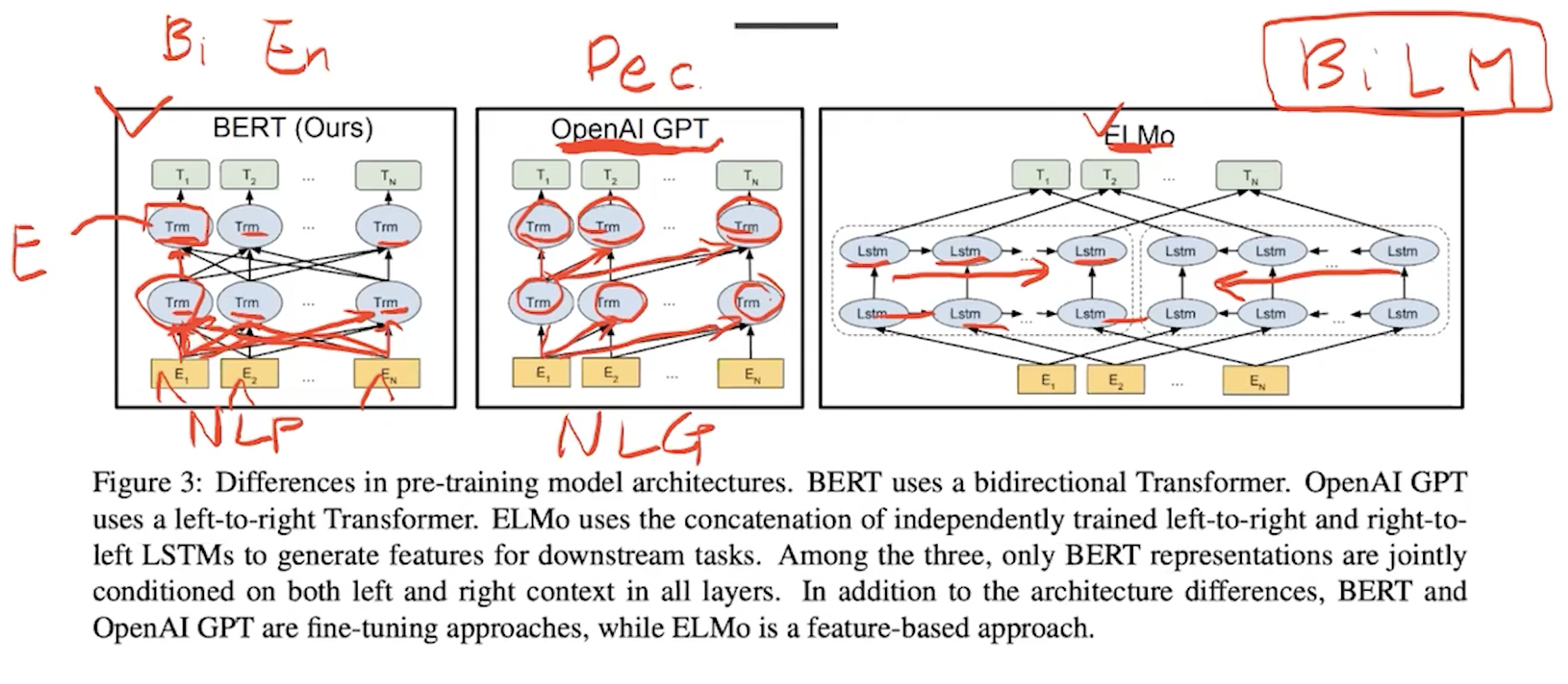
encoder만 사용해서 양방향
gpt는 decoder로 예측에 쓰이므로 단방향
al bert 경량화된 bert
7. 실습
tensorflow.org/tutorials/text/transformer
패딩은 어순에 의해 결정되기도 한다.
코드만 보면 너무 어려우니 이론을 이해하고 코드와 매핑하여 이해한다.
dk = tf.cast(tf.shape(k)[-1], tf.float32)
포르투칼어 -> 영어 번역 데이터셋
8. 참고
huggingface.co/transformers/
sota모델이 나오면 다 패키지화한다.
9. 조언
직접 구현을 하고 그 후에 패키지를 써라
pytorch로 구현하고 참고 링크에 있는 패키지를 사용하자.
논문 이해 -> 논문 코드 이해 -> 구조를 알고 활용하면 튜닝에 훨씬 효과적이다.
'이제는 사용하지 않는 공부방 > Artificial intelligence' 카테고리의 다른 글
| cuda pytorch (0) | 2021.10.26 |
|---|---|
| BERT (bidirectional encoder representations from transformers) (0) | 2021.10.04 |
| how to decide number of layers and number of neurons (0) | 2021.09.20 |
| 자꾸 헷갈리는 axis 정리 (0) | 2021.09.14 |
| 자연어처리 이론 한번에 정리하기 (0) | 2021.09.01 |