pre-training of deep bidirectional transfomers for language understanding
이전의 단점을 보완하기 위해서 어떤 것들을 했는지 보는 것이 중요하다.
경량화 -> albert
돈 퍼붓기 -> 성능 -> gpt3 ( pre-training, 150억 )
context vector로 바꾸는 encoder의 역할을 활용하여
language understanding을 한다.

pre-trained model + fine tuning
multi layer
bidirectional transformer (encoder)
성능 비교
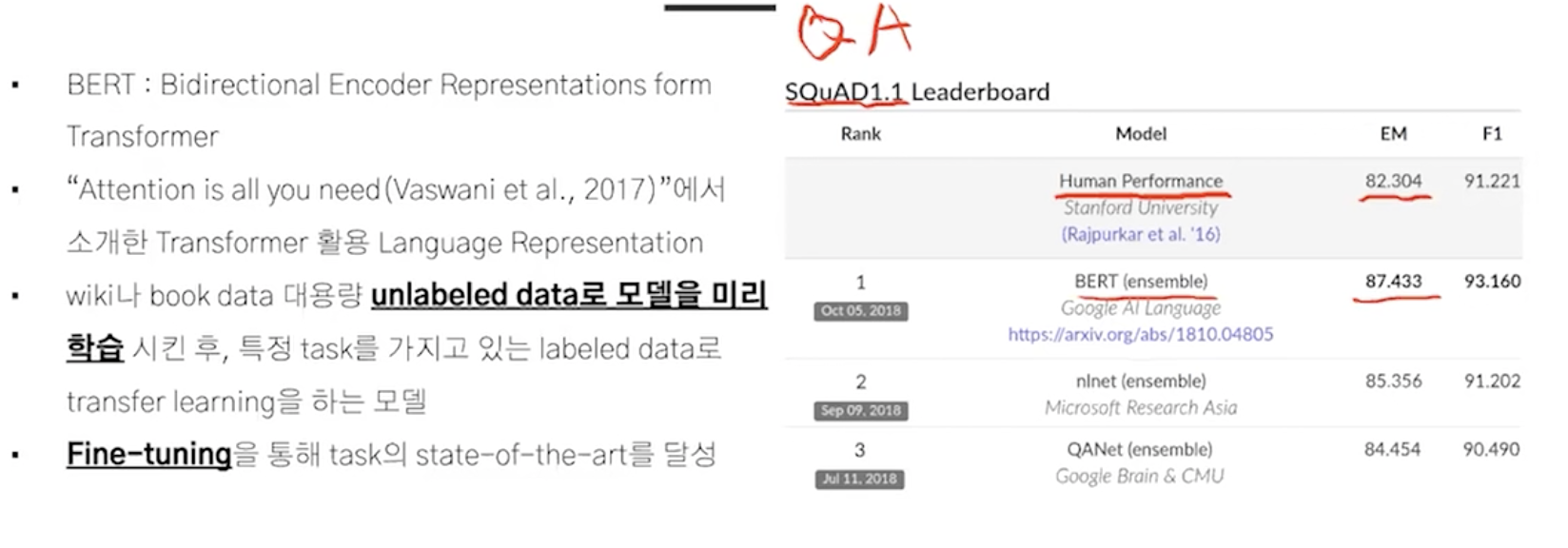

질문: elmo는 feature based approach인 반면에 bert, gpt는 fine-tuning based라는데 이유가 뭐지?

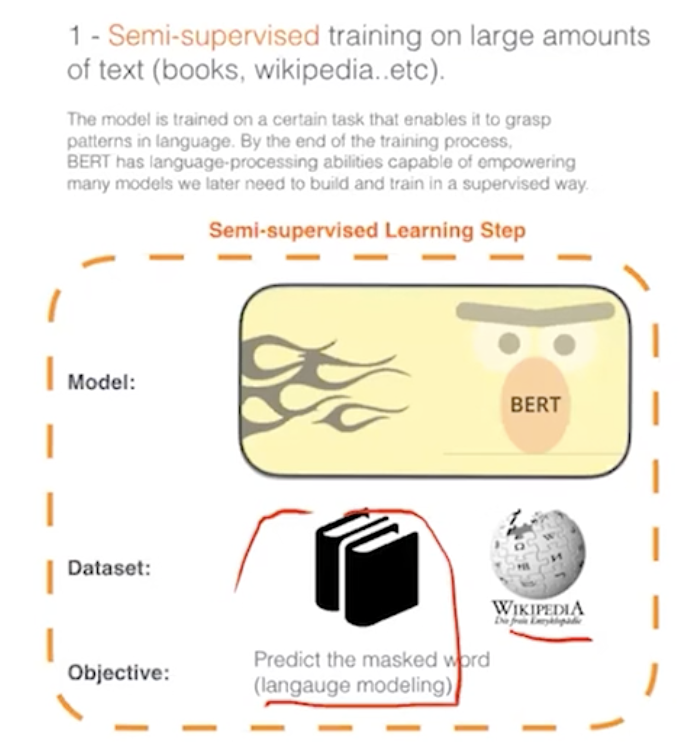
엄청 큰 corpus(10억개)에서 pre-training을 하면 언어를 이해하고 이를 가져와서 특정 task에 fine-tuning을 한다.

두 문장씩 들어간다. 현재 문장과 다음 문장간의 관계도 파악을 한다. next sentence prediction

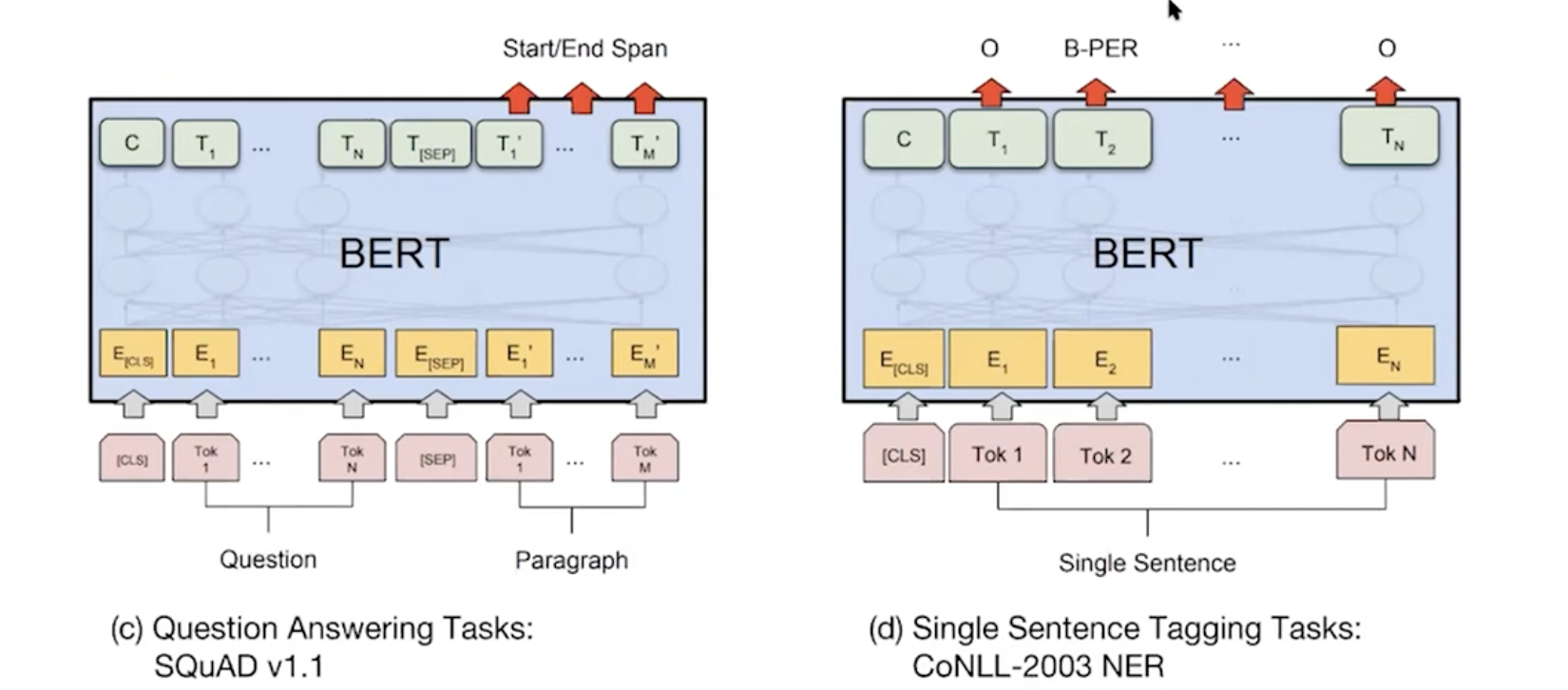
답변을 담고 있는 단락이 있고 거기에 답변의 위치가 start, end로 있다.
학습의 방법에는 두가지가 있다.
문맥을 이해하고 맞추는 게 목적
1) masked language model 특징 1
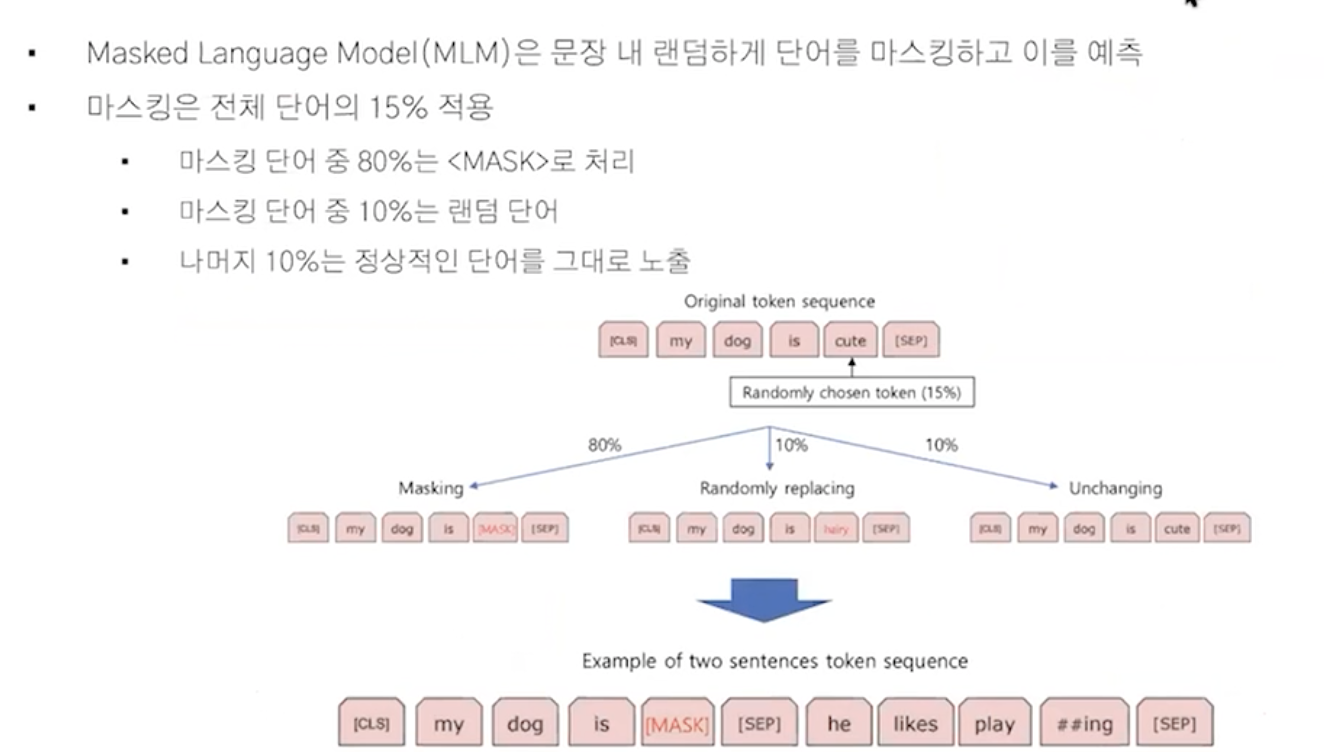
encoder의 특징인 문장안에 토큰을 이해하고 마스크된 토큰을 예측할 수 있다.
단어를 바꿨을때 정답을 맞출 수 있도록 학습하는 게 목표
2) next prediction model 특징2
첫 문장 -> 두 번째 문장
qa, chatbot에 도움이 된다.

50%는 랜덤하게 틀린 문장이다.
사람이 라벨링하지 않고 코퍼스 안에서 마스킹을 통해서 혹은 다른 데이터로 교체하기때문에 ,unsupervied learning라고 한다.
0. input representation
word piece model로 토큰화를 하고 아래의 과정으로 만든다.

segment embedding은 문장을 구분한다. 1번 문장은 0으로 2번 문장은 1로 바꿔준다.
1. token embedding

2. segment embedding

3.position embedding
transformer 참고
특징 3 tokenizer: word piece model
*토크나이저를 알기 위한 사전 지식

카이라는 한국어 형태소 분석기는 byte pair encoding을 사용한다.

자연 -> dic
연어 -> dic
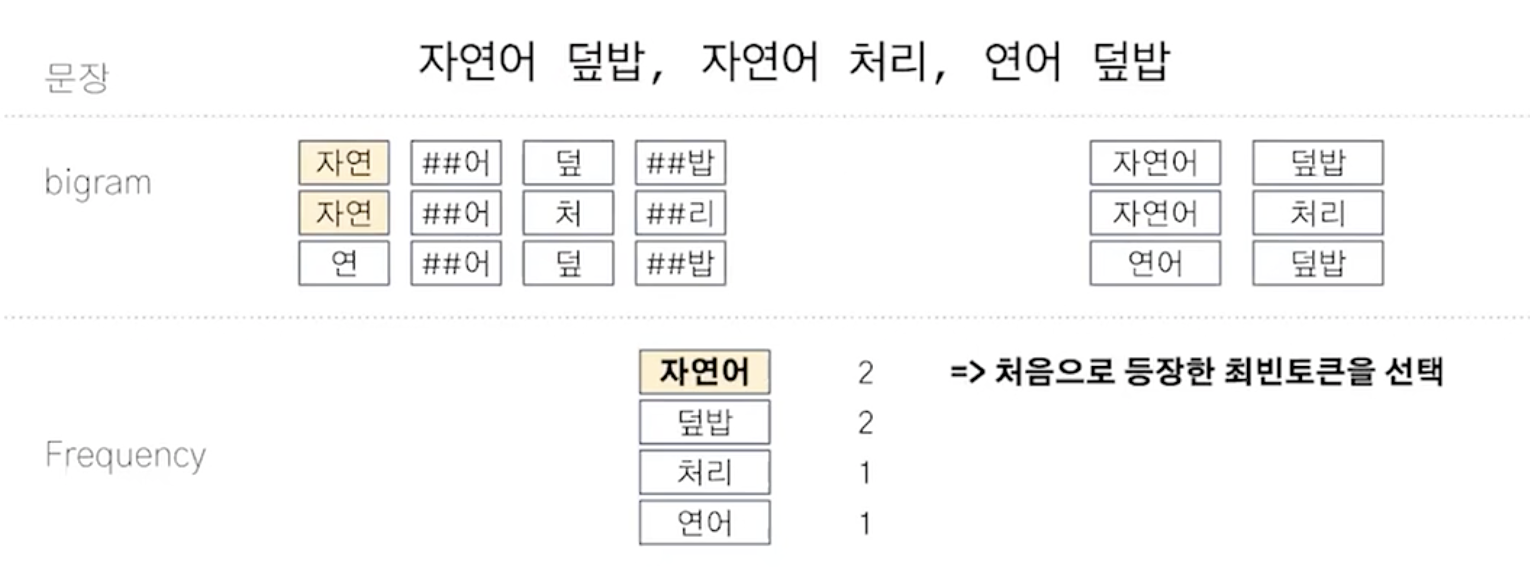
...subword(등장하지 않은 단어)에 대한 학습이 가능하다.
데이터에 특화된 토크나이저를 만들 수 있다. ( 의류, 금융 등..)
word piece model 다시 보기
hugging face에 데이터셋 넣어주면 도메인에 특화된 토크나이저를 리턴해준다.
1. pre-training
2. fine-tuning

4. koBERT

성능이 3개의 task에서 더 좋게 나왔다.
형태소 분석기만을 개선해서 성능이 좋아졌다.
모델의 구조 이해
'이제는 사용하지 않는 공부방 > Artificial intelligence' 카테고리의 다른 글
| cuda pytorch (0) | 2021.10.26 |
|---|---|
| Transformer ( attention is all you need ) (0) | 2021.10.01 |
| how to decide number of layers and number of neurons (0) | 2021.09.20 |
| 자꾸 헷갈리는 axis 정리 (0) | 2021.09.14 |
| 자연어처리 이론 한번에 정리하기 (0) | 2021.09.01 |